Risks in Software Development: How to Match Your Caution to What’s Actually at Stake

In this article
- Where the risks in software development actually live
- The six types of software development risk
- The dangerous changes are the ones that look like nothing
- The most reliable way to lower risk is boring
- The risks that cost the most aren’t in the code
- Reading risk is the developer’s job now
- Frequently asked questions
- Build a team that reads risk well
On July 19, 2024, CrowdStrike shipped a routine update to its security software. One bad file took down about 8.5 million Windows machines and grounded flights, froze banks, and knocked hospital systems offline for the better part of a day.
The engineer who pushed it almost certainly thought it was a small change.
That’s the whole problem with how we usually talk about risk. The standard “risks in software development” checklist (budget, schedule, scope creep, technical and security risk) is a project manager’s list, the kind that gets reviewed once at a kickoff and filed away. It won’t help you on a random Tuesday afternoon when you’re staring at a one-line change that could quietly take down production.
Because here’s the question nobody teaches you to ask before you touch anything: what’s the worst thing that happens if I’m wrong here? A config tweak and a change to the code that charges a customer’s credit card can look basically identical in a pull request. They are not even close to the same risk, and knowing which is which is most of the job.
Every change you make has a blast radius. A good engineer reads it before they write a line and lets it decide how careful to be. This is a guide to reading it, written for our own engineers at Full Scale as much as anybody, because it’s the whole difference between a developer who moves your business forward and one who just closes tickets.

Where the risks in software development actually live
Risk isn’t something you assess once at kickoff and file away. It’s a question you answer every single time you open a pull request, and it comes down to two things: how much damage this change can do if it’s wrong, and how hard it is to undo.
Think about how wildly different the software inside one company is. Code that launches a rocket has to be flawless, because you can’t patch a spacecraft that’s already halfway to orbit. Code that runs some internal dashboard three people glance at on a slow Friday can be broken all week and nobody notices. Same language, same craft, but the stakes aren’t in the same universe.
The skill is matching how carefully you work to how much damage a mistake can actually do.
The easiest way to think about the reversibility half is a one-way door versus a two-way door. A two-way door you can walk back through: a feature behind a flag, a config tweak, a deploy you roll back with one click. A one-way door you don’t get back from without a ton of pain: the core architecture everything else is built on, a migration that rewrites millions of rows, a giant cutover that swaps everything at once. Almost all your day-to-day work is a two-way door. It’s nowhere near as scary as it feels, and you should be flying through it. Save the white-knuckle caution for the one-way doors.
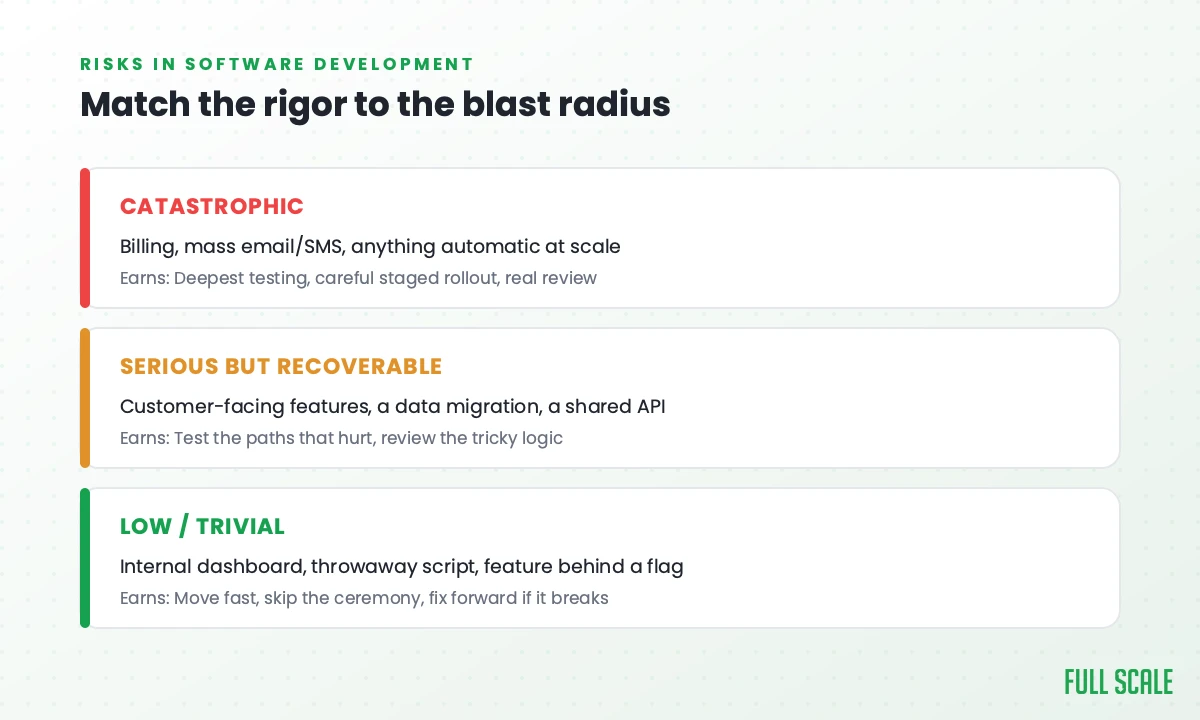
The damage half runs on a spectrum, and roughly three levels of it each earn a different amount of care.
The stuff that can’t be wrong even once touches money or fires messages at scale: billing code that double-charges a card, a job that emails your whole list, the CrowdStrike-class update that repeats one bug ten thousand times before a human looks up. This earns your deepest testing, a real review from someone who knows the system, and a slow staged rollout.
The stuff you can recover from, but it’ll sting is where most of your real work lives, and it’s the hardest to judge: a customer-facing feature, an API change a few clients depend on, a data migration. The trap is that a migration can look reversible and quietly corrupt data you won’t notice for weeks. Test the one or two paths that actually matter (on a checkout change, the part that takes the payment, not the order-history label), get a second set of eyes on the tricky logic, and make sure you can re-run it safely if it dies halfway.
The stuff nobody will remember by Friday is the throwaway script, the internal dashboard, the feature behind a flag only your team can see. Worst case, you fix it in twenty minutes and nobody outside the building knew. Move fast and skip the ceremony; piling process onto this is pure waste.
So before you start, run the change through a few quick questions. What’s the worst case if I’m wrong: money, data, customer trust, or just a quick fix? Can I undo it in seconds, or am I committed once it ships? How many people does it touch if it breaks? And do I actually understand how this behaves in production, not just on my laptop? The answers set your rigor. High-stakes changes earn deep testing on the paths that actually matter, a real review, and a staged rollout. The low-stakes stuff earns almost none of that.

This is also exactly how much testing each piece deserves, which is why we treat testing depth as a leadership decision, not a QA checklist and security as practices baked into the work rather than a step bolted on at the end.
The six types of software development risk
Most lists identify the same six risks. These lists are adequate, but there is a consistent issue- they are usually filled out once at kickoff, copied and pasted into a risk register, and never opened again. Below, I will deal with the more qualitative sides of each of these risks.
Technical risk
This is the most common. Picture a wrong database, a framework that collapses under your load, or integration held together with tape. These are exciting versions that are rarely the ones that get you.
In most working companies, the most significant risks are the technical debt you currently have. Every shortcut taken two years ago is now sitting there, silently making today’s change more risky than it should be. At the time, no one registered it as a risk, because it wasn’t a risk. But over time this has changed.
So, the most useful question is not whether the technology is good. The real question is how big of a reach this change is and whether it is possible to put it back. An upgrade of a service dependency that touches all of the services will come with more risks than a database that you will complain about for three years.
Schedule risk
The common attitude towards deadlines seems to be, “We might be late.” Being late seems normal. The important question is, what did you set the date to? A two-week slip on an internal roadmap is an annoyance at best. A date slip in two weeks that your CEO gave to a customer, now that’s a problem, even though the code is the same in both situations.
Shipping the product is presumed to be the finish line, but that’s not how it works. One engineering leader at AMC Theatres described a typical week like this: “Every Monday, we do a production release. Then, there are two hotfixes on Tuesday, one on Wednesday, and if we are lucky, nothing on Thursday.” That sounds bad, but it’s completely routine. Bigger releases are even accompanied by bigger pullbacks.
If your plan includes the team starting a new project the day after a major release, you are being unrealistic. I consider every timeline a hypothesis, not a promise. This means being candid about which dates are priorities and which ones are just aspirational goals.
Budget risk
It’s easy to say this is about overspending, but framing it that way misses the target. A project that doubles its budget but launches something that customers actually want is a success. A project that comes exactly on budget and launches something that no one interacts with is a total loss, even if the paperwork is impeccable.
What you should be worried about is not how much cash you have exchanged, but how much you are committed without having any knowledge first. The most expensive decisions get made earliest, when you know least about the problem, and everything built after that locks them in. That is the whole reason for spending a little bit to learn quickly. The cheapest thing in this article is a throwaway prototype that costs a week and eliminates a bad idea.
Scope risk
Everyone tries to solve this with some sort of process, and the change-control gate almost never works. Scope creep is the shadow side of the ownership you want from engineers. The same good instinct that sends an engineer to fix a broken thing they noticed on the way past is what turns a two-week feature into a five-week feature.
You don’t solve that with another form. To solve this problem, you have to teach people which value-adding tasks are worth the effort, and that requires them to understand what the business is actually up to. A developer who understands the purpose behind the feature can make that decision correctly. A ticket closer cannot make that decision, so the scope just quietly grows and nobody can explain exactly when it happened.
Security risk
As far as risk factors go, security will always be a non-recoverable issue. A bad deployment can be reversed, but customer data or customer leaks cannot be undone. No matter how hard you work the next morning, once data is leaked, the damage cannot be undone.
This is the reason that, regardless of actual change size, security code changes are always highly prioritized. Even with a small number of changes, it is more important to focus on code that controls session validation than code that controls an admin dashboard. Changes that pose security risks are far more important than changes that do not. The size of a change should not determine the attention it receives in security changes. What matters is the damage it does if it cannot be undone.
Vendor and people risk
Vendor and people risk is the last on the list, but probably the most important. The developers you choose to hire are a risk you take. So is the agency you choose to work with, the API that you choose to build your product on, and the vendor whose service disruptions happen at 9am.
When something goes wrong in outsourcing, it is usually a contextual issue and not a skills issue. It is highly likely that the person on the other side did not realize which parts of a system were load-bearing, and so treated all components the same, which means they treated the critical components just like the non-critical ones. That is not a coding problem, and you don’t solve it by finding somebody cheaper.
Revisiting those six risks raises the same concern: what if this is incorrect, and is there a way for me to reverse it?
The dangerous changes are the ones that look like nothing
The hardest part of reading a blast radius is that the riskiest changes often look like the safest. This is where developers who’ve never really lived in production get wrecked.
Adding an index to a table feels like nothing on your laptop. The table’s got a few thousand rows, the change runs instantly, you commit it and move on. Then it hits production, where that same table has 500 million rows, and that “instant” change locks the whole table, grinds for hours, and drags the app to a crawl during your busiest traffic of the day. What was a one-line migration on your machine needed a planned maintenance window and a careful rollout in the real world.
The risk was never in the code. It was in the gap between what your laptop looks like and what production actually looks like.
You can’t judge a blast radius you’ve never seen. A developer who’s never watched a system buckle under real load, with real data and real traffic, will keep mistaking grenades for water balloons. That’s the most common way genuinely good engineers cause genuinely bad outages, and it’s why understanding the production environment isn’t optional.
The most reliable way to lower risk is boring
When something breaks, the cause is almost always whatever just changed. A system that worked yesterday and faceplants today doesn’t need you spelunking through the whole codebase like a detective. It needs you to ask what changed since the last time it worked. But that only saves you if the answer is small. Ship one tight change and you find the culprit in minutes. Ship a giant release with forty things crammed in and you’re interrogating forty suspects while production is on fire.
So the single most reliable way to lower your risk is dull as hell: ship lots of small changes instead of a few big ones. A small change is easy to understand and easy to roll back. A big release buries the cause of every problem under a mountain of noise.
The rollout is the other half. You don’t have to flip a risky change on for everyone at the same second. Feature flags let you split shipping the code from releasing the feature, so you turn it on for a tiny group, watch what happens, and widen only once it holds.
Bugs are going to happen no matter how good you are, so the smart play is to catch them while the blast radius is tiny. Picture Tesla pushing an update to every car on the road in one night. Something’s wrong, and the whole fleet is broken by breakfast. Now picture them shipping to a few thousand cars first, watching, then widening. Same update, but the risk is completely different.

The risks that cost the most aren’t in the code
But all of that only helps if you actually calibrate in the first place, and fear pushes most people the wrong way. It isn’t their company, and a mistake feels like it could torch their reputation or their job, so they over-review, over-test, and beg for permission on changes that carry no real risk. The whole team slows down to guard against downsides that were never going to be a big deal.
I notice this because I don’t feel it. I’m the founder. If I break something, I’ll fix it, and I’m not about to fire myself over it. An employee doesn’t get to feel that loose, and that’s fair. I’m not telling anyone to care less. The trick is knowing when to white-knuckle a change and when to ease off. And if you’re new to the system or just not sure, treat the change as scarier than it looks and get a second read. You earn the right to move fast by watching real systems break, not on day one.
But over-caution isn’t even the expensive mistake. The expensive one is pouring all that rigor into the wrong thing. We needed a quick internal tool a while back, a dirty little MCP server, the kind of thing that should’ve taken two or three days. Instead the guys on our team decided to architect it properly and spent six weeks on it. When they finally shipped, it didn’t even work right, because in six weeks of building it properly not one of them let a real person try it. The risk they should’ve been sweating wasn’t “is this elegant enough.” It was “are we even building the right thing.”
That’s the biggest risk in all of software development, and it sits underneath every other one: that the work isn’t worth doing at all. You can write flawless, beautifully tested, perfectly rolled-out code for a feature nobody asked for. At Stackify, we once dropped $10,000 sponsoring a developer conference to launch a product and walked away with exactly zero new customers. The product just wasn’t what people needed, and no amount of clean code was going to fix that. We learned it a quieter way too: we assumed more usage meant more value and optimized to get people logging in more often, then we actually listened, and customers told us the opposite. “I just need to know why production is broken.” They didn’t want to live in our app. The most valuable thing we could build was the thing that got them out of it faster.
Shipping the wrong thing efficiently is still shipping the wrong thing. Getting real feedback early beats almost any other risk control there is, which is the whole heart of asking why before you build, something I bang on about constantly in Product Driven.
Reading risk is the developer’s job now
For a long time the industry treated developers like order takers. Requirements rolled downhill, you built what the ticket said, and judgment was somebody else’s department. That model is dead.
Now that AI cranks out so much of the code we ship, the bottleneck isn’t typing anymore. It’s judgment. A developer has to understand the business problem, weigh the risk of the different ways to solve it, and go solve it without a permission slip at every step. The 2025 DORA report put it well: AI amplifies whatever’s already there. Strong teams get faster and better with it, while weak teams just ship their problems quicker. Either way, the judgment comes from you, not the tool.
This is the real difference between a developer who multiplies a team and one who quietly drains it, and it has nothing to do with speed or lines of code. It’s whether they can read risk and move accordingly, flooring it where it’s safe and easing off where it isn’t. The one who treats every change like he’s launching a rocket is as much of an anchor as the one who treats a billing change like a throwaway script.
That judgment is also exactly what you’re paying for when you hire a senior engineer, and exactly what you’re not getting when you chase the cheapest warm body you can find. We call that mistake cheapshoring. A cheap dev can type code. Reading the blast radius of a change, in your system, against your business, is the part that takes real experience.
Frequently asked questions
What are the main types of risks in software development?
The standard lists name a half-dozen or more: technical, schedule, budget, scope creep, security, sometimes resourcing and vendor risk. Some are real engineering concerns and some are project-management ones, and cataloging them at a kickoff is fine as far as it goes. The one those lists tend to miss is the blast radius of each change you make: what’s the worst thing that happens if this specific piece of code is wrong, and how hard is it to undo? That’s the version a developer can actually act on. The same is true of scope creep, which is more a leadership problem than a process one.
How do you assess software development risk?
Per change, not just per project. For anything you’re about to ship, ask what the worst case is if it fails, whether you can reverse it, and how many people or how much money it touches. The bigger those answers, the more testing, review, and careful rollout it earns. Low-stakes work earns almost none.
How do you mitigate risks in software development?
The habits that matter are dead simple. Ship small changes instead of giant releases, so you always know what changed when something breaks. Use feature flags to roll the risky stuff out to a small group first. Concentrate your testing on the code that can actually hurt the business. And get real user feedback early, before you’ve built the wrong thing really well.
Does AI change the risks in software development?
It raises the stakes on judgment. AI can spit out code far faster than a person can carefully review it, so the risk of shipping something nobody truly understood goes up. The 2025 DORA research found AI amplifies whatever a team already is. Disciplined teams ship faster and safer, while teams with sloppy habits just produce their mistakes quicker.
Build a team that reads risk well
Managing software development risk well is a learned skill, and it’s the whole difference between an engineer who speeds your company up and one who quietly slows it down. It’s exactly what we train for at Full Scale, where our engineers work as part of your team through our staff augmentation model instead of as some vendor taking orders. If you want to scale with developers who actually own that judgment, book a call and let’s talk.


