Signs Your Backend Needs a Rebuild (and When a Refactor Is the Smarter Call)

In this article
- Why the full rewrite is the most dangerous call in software
- The fake signs that trick teams into a rebuild
- The real signs a backend rebuild is justified
- The story behind both: VinSolutions and Stackify
- AI is changing the math, in both directions
- If you do rebuild, here’s how not to blow it up
- Frequently asked questions
A backend rebuild is the most confident decision a team can make, and most of the time it’s the wrong one.
I’ve watched a lot of teams talk themselves into throwing out a working system and starting over. The code is old. A new senior hire hates it. A shinier framework came out. So they pitch a rebuild, the business says yes, and a year later they’ve spent a fortune to arrive at roughly where they started, minus the edge cases the old system had quietly handled for years.
I’ve made this call with my own money. At Full Scale we now work inside a lot of client backends, some of which genuinely needed rebuilding and most of which didn’t. So before you greenlight a rewrite, let me give you the honest version: the fake signs that trick teams into a backend rebuild, the real signs that actually justify one, and how to tell them apart. If a backend rebuild also means moving to the cloud, treat the cloud transformation services question on its own: the migration ends, but your team still has to run the result. However you rebuild, treat the delivery layer as code as well; infrastructure as code is what keeps the new system reproducible.
Why the full rewrite is the most dangerous call in software
When you rewrite a backend from scratch, you’re betting that a clean slate will be faster than fixing what you have. The same over-confidence shows up in the monolith vs microservices decision. That bet almost always loses, for one reason: the messy old code is messy because it’s true.
Every weird conditional and ugly workaround in a mature backend usually encodes a real bug someone hit, a real edge case a customer ran into, a real thing that broke at 2 a.m. Throw the code away and you throw away that knowledge. You don’t get a clean slate. You get a system that has to re-learn every lesson the old one already knew, while the old one keeps running and the business keeps asking why the new one isn’t done yet.
Meanwhile the rewrite ships nothing for months. Your competitors don’t stop. The “two quarters” estimate becomes four, then six, because nobody included the boring 20 percent of features that took 80 percent of the original effort.
That’s why my default answer to “should we rebuild the backend” is no, refactor it. You change it in place, piece by piece, while it keeps working. The rebuild is the exception you have to earn, not the default.
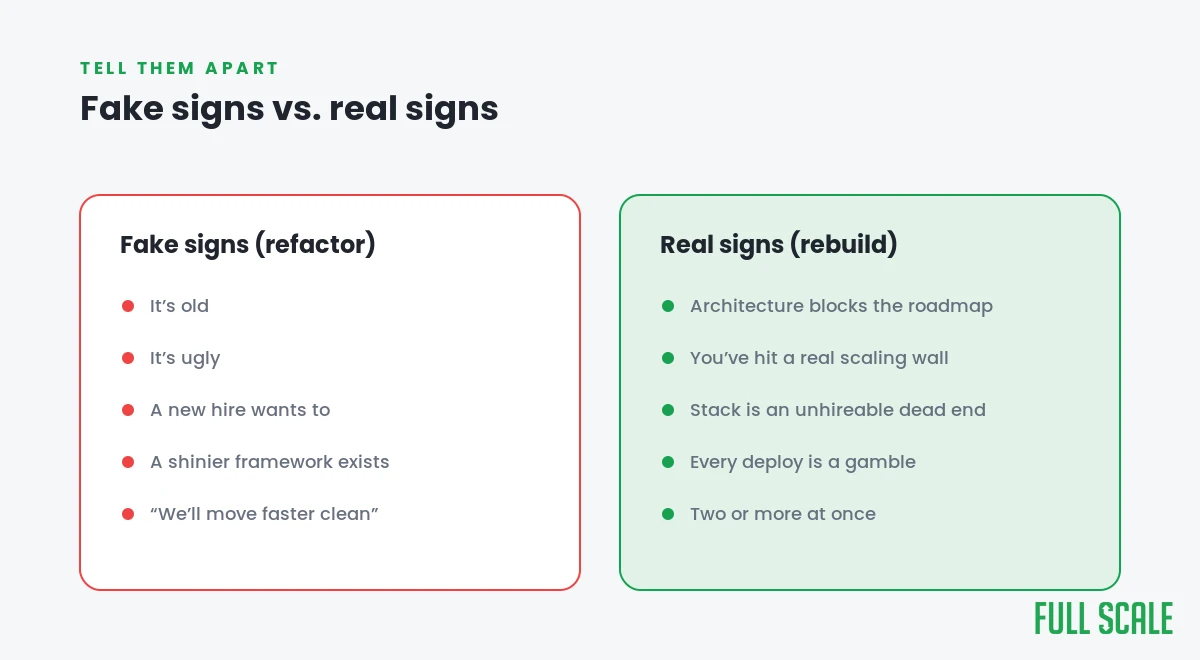
The fake signs that trick teams into a rebuild
These are the reasons I hear most often, and none of them justify a rebuild on their own.
“It’s old.” Age isn’t a problem. I scaled a backend to a nine-figure exit on technology that was already unfashionable at the time. Old and boring and working beats new and exciting and unproven almost every time.
“It’s ugly.” Ugly code that works is an asset. A senior engineer’s discomfort with the previous team’s style is not a business case. Refactor the parts you touch.
“A new hire wants to.” A strong engineer who just joined will almost always want to rewrite what they don’t yet understand. That’s a signal they haven’t learned the system, not that the system is wrong. Give it three months.
“There’s a better framework now.” There’s always a better framework now. Migrating to it is a cost with no customer-facing payoff unless the current one is actually blocking you.
“We’ll move faster on a clean slate.” You won’t. You’ll move slower for a long time while you re-implement everything the old system did, including the parts nobody documented.
If your reasons for a backend rebuild are on this list, you’re looking at a technical debt problem you can refactor your way out of, not a rebuild.
The real signs a backend rebuild is justified
Now the other side. These are the signs that a rebuild is the right call, and the pattern is the same in all of them: the architecture is blocking the business, not just annoying the engineers.
The architecture blocks what customers are paying for. When the thing your customers want next is impossible to build on the current design, not hard, impossible, that’s a real sign. If adding the feature would mean rebuilding half the backend anyway, the rebuild is on the table. Outgrown template storefronts are the classic case here, which is why so many custom e-commerce builds start life as exactly this kind of rebuild decision.
You’ve actually hit the scaling wall. Not “we might need to scale someday.” You’ve hit it, the cost of serving more load is climbing faster than the load itself, and you’ve already squeezed the obvious wins. Real scale problems justify real architecture changes. Imagined ones justify nothing. More on this in our piece on software scalability.
The stack is a genuine dead end. The runtime is unsupported, the framework is abandoned, the security patches stopped coming, and you can’t hire anyone who’ll touch it. That’s not aesthetics. That’s risk, and it compounds. The same judgment applies to an aging mobile codebase, which is the heart of what to do with a legacy Objective-C codebase.
Every change is a gamble. There are no tests, nobody fully understands the system, and each deploy has a real chance of taking production down. When the cost of changing the code safely exceeds the cost of rebuilding it with tests and structure, the math finally favors a rebuild.
When two or more of these are true at once, you’re not avoiding a rebuild anymore. You’re choosing the right one.
The story behind both: VinSolutions and Stackify
I’ll give you the two ends of this from my own career, because they’re the clearest version of the decision.
At VinSolutions, the number one CRM in automotive, we scaled to $35 million in annual recurring revenue on essentially one big database server, a maxed-out Dell, plus read replicas. Plenty of smart people would have looked at that architecture and called for a rebuild into something modern and distributed. We didn’t, because it wasn’t blocking the business. It was ugly and it was old and it worked, so we put our money into the product instead. A rebuild there would have been the most expensive mistake we could have made.
The part I left out is what scaling that database in place actually looked like. As we grew, one big SQL Server stopped being enough, and plenty of smart people would have called for a ground-up rebuild into something modern and distributed. We didn’t. We added read replicas to carry the read load, which was fragile and cost us plenty of bad nights, and we pulled the busiest tables out onto their own database servers to relieve the main one. None of it was elegant, and it kept a nine-figure company running while we spent our money on the product instead of a rewrite. Refactoring under load is uncomfortable and unglamorous, and it still beats the rewrite almost every time.
At Stackify, the opposite was true. We ran around 2,000 sharded SQL Server databases to ingest application logs and performance data at a volume no single database could hold. That was a real scaling wall, and the architecture had to change to match it. The rebuild was justified because the load was real, not theoretical.
The difference was never the age or the elegance of the code. It was whether the architecture was actually in the way.

AI is changing the math, in both directions
A backend rebuild decision in 2026 has to account for AI, because it’s pushing the debt in both directions.
It’s adding debt faster. GitClear’s analysis of 211 million lines of code found that duplicate code blocks jumped about eightfold in 2024 while refactoring fell below 10 percent of changed lines. AI is great at generating more code and bad at consolidating it, so the average backend is accumulating mess faster than before. And a 2025 Veracode study found 45 percent of AI-generated code carried a known security flaw. Some of that “we need a rebuild” feeling is really AI-generated debt piling up.
But AI also makes the refactor cheaper than it used to be. The same tools that generate sloppy code are very good at the grunt work of refactoring, adding tests, and untangling old logic when a senior engineer directs them. As the DORA 2025 report put it, AI amplifies what’s already there: a strong team uses it to pay down debt, a weak team uses it to ship more debt faster. That cuts toward refactoring more often than it cuts toward a rebuild, because the in-place fix just got a lot more affordable.
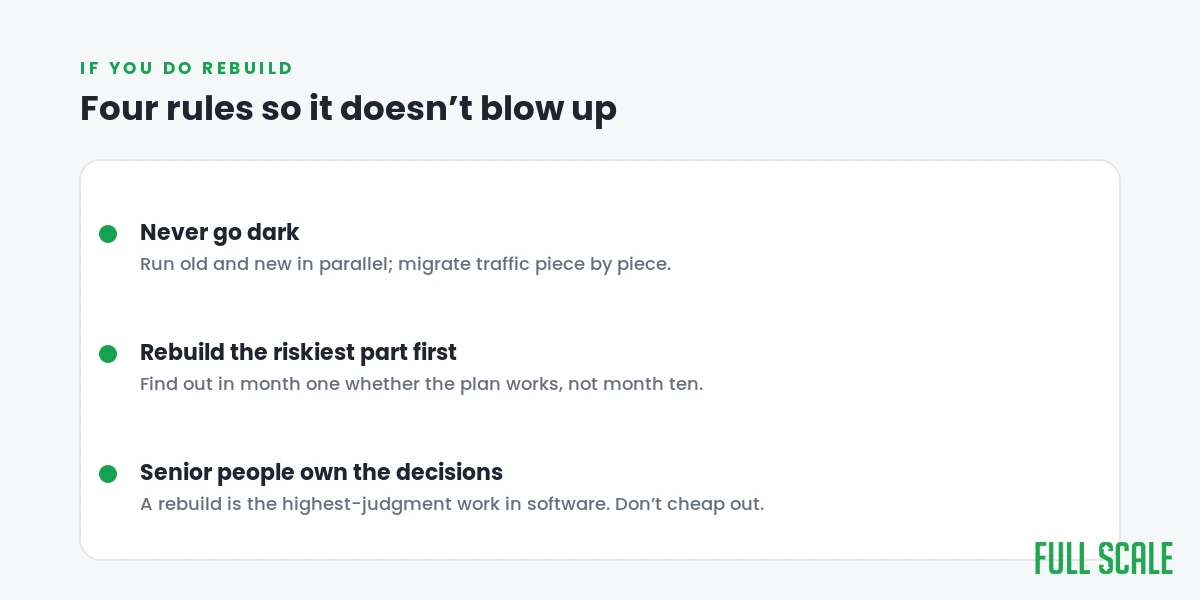
If you do rebuild, here’s how not to blow it up
If you’ve honestly hit the real signs, a few rules from having done it.
Never stop the old system to build the new one. The same caution applies when you migrate between SQL and NoSQL. Run them in parallel, move traffic piece by piece, and keep a working product the whole way. The big-bang rewrite that goes dark for a year is the version that fails.
Rebuild the riskiest piece first, not the easiest. If the scary part can’t be rebuilt cleanly, you want to know in month one, not month ten.
Put your most senior people on it, or get senior help. Senior judgment sits at the top of the backend developer skills list. A rebuild is the highest-judgment work in software, and it’s exactly the wrong place to save money on the cheapest available engineer. It is the kind of call you want a senior backend engineer making. The decisions made in the first weeks set the cost for years, which is the same lesson as what backend development actually costs: the rate is cheap, the judgment is everything.
And keep the old edge cases. Before you delete anything, write down what it did. That ugly conditional is institutional memory.
This is really the same idea I keep coming back to in my book, Product Driven: spend your effort on what actually moves the business, and be honest about what doesn’t. A rebuild that serves the architecture’s vanity instead of the customer’s need is the most expensive form of building the wrong thing.
If you’re trying to decide whether your backend needs a rebuild or a refactor, and you want senior engineers who’ve made that call before, schedule a call with us.
Frequently asked questions
How do I know if my backend needs a rebuild or just a refactor?
Refactor when the code is messy, old, or ugly but still does its job, which covers most cases. Rebuild only when the architecture actively blocks what the business needs to build next, you’ve hit a real scaling wall, the stack is an unsupported dead end, or every change risks taking production down. If your reasons are about taste or fashion, it’s a refactor. If they’re about the architecture standing between you and your customers, it may be a rebuild.
Why are software rewrites so risky?
Because a mature backend’s messy code usually encodes years of real bug fixes and edge cases, and a rewrite throws that knowledge away. You spend months re-implementing what the old system already did, ship nothing customer-facing in the meantime, and routinely blow past the estimate because the boring last 20 percent of features takes most of the effort. The old system keeps running while the new one struggles to catch up.
What are the real signs a backend rebuild is justified?
Two or more of these being true at once: the architecture makes a feature customers are paying for impossible to build, you’ve genuinely hit a scaling wall where cost grows faster than load, the technology stack is unsupported and unhireable, or the system is so fragile and untested that every deploy is a gamble. The common thread is that the architecture blocks the business, not just that the engineers dislike it.
Does AI make a backend rebuild more or less necessary?
Both. AI is adding code and duplication faster than teams refactor it, so backends accumulate debt more quickly, which can feel like a reason to rebuild. But AI also makes refactoring, testing, and untangling old code much cheaper when a senior engineer directs it, which usually tips the decision toward an in-place fix rather than a full rebuild.
How should I approach a backend rebuild to avoid failure?
Keep the old system running and migrate piece by piece rather than going dark for a big-bang rewrite. Rebuild the riskiest component first so you learn early whether the plan works, put your most senior engineers on the architecture decisions, and document every edge case the old system handled before you replace it. The first few weeks of decisions set the cost for years.


