Offshore Backend Development: The 4 Things That Actually Break (and How We Fix Them)

In this article
- Why offshoring the backend is different from the frontend
- 1. Data model and schema decisions
- 2. API contracts falling out of sync
- 3. Infrastructure and DevOps ownership
- 4. On-call and production incidents across time zones
- The one decision that makes all four fixable
- When offshore backend development works, and when it doesn’t
- Frequently asked questions
- The bottom line
QUICK ANSWER: Offshore backend development works, but it is harder to get right than offshore frontend work. The backend is where your irreversible decisions live: the data model, the API contracts, the infrastructure, and who answers the phone at 3am. Most offshore backend failures trace back to one of those four things, and all four are fixable with the right team model. This guide covers what breaks and how we fix it. The model applies stack by stack. When the backend is Python, you can hire offshore Django developers on the exact terms described here.
I have spent most of my career on the backend. I was the CTO and co-founder of VinSolutions, where we scaled to $35 million in annual recurring revenue before the acquisition. I founded Stackify, a developer-tools company built on top of a backend that ingested performance data from thousands of applications. Now I run Full Scale, where we have placed more than 1,000 developers with over 200 tech companies since 2018.
So when a CTO asks me whether they can offshore their backend, I do not give them the brochure answer. I tell them the truth: the backend is the highest-stakes thing you can offshore, and that is exactly why most people do it badly.
Why offshoring the backend is different from the frontend
A frontend mistake shows up on the screen. You see the broken button, you file the bug, you ship the fix that afternoon. The cost of being wrong is low because the work is visible and easy to reverse. Backend teams own the delivery side too, from CI/CD pipeline automation to who carries the pager.
The backend does not work that way. A bad schema decision shows up six months later as a migration that takes three engineers two weeks. A sloppy API contract shows up as a production outage nobody can explain. These mistakes compound quietly while everything looks fine on the surface. The difference between frontend and backend work runs deeper than most hiring guides admit, and it is exactly why the two should not be offshored the same way.
The backend is where the irreversible decisions live, so the cost of getting the team wrong is much higher there.
That is the real reason offshore backend projects fail. It is rarely the developers, and it is almost never the time zone. It is that companies offshore the backend the same way they offshore a marketing site, then act surprised when the stakes turn out to be different. Here are the four things that break, and how we keep them from breaking.

1. Data model and schema decisions
The data model is the one decision you cannot easily walk back. Once you have millions of rows in a table, changing the shape of that table is surgery. I have watched teams spend a full quarter unwinding a schema choice that took an afternoon to make.
This is where distance hurts the most. When the engineer designing your schema does not understand your product or your customers, they optimize for the wrong thing. They normalize something that should have stayed simple, or they bolt on a column that should have been its own table. You inherit that decision for years.
Here is the part most vendors will not tell you: scaling a backend is mostly boring, and that is good news. The cloud already solved the expensive parts, and the patterns for building reliable systems on it are well documented in AWS’s Well-Architected Framework. For the large majority of products, you need stateless app servers, files in shared storage, a queue for slow work, sensible indexing, and some caching. At VinSolutions we ran to $35 million in ARR on essentially one big database server and a set of read replicas. I babysat a maxed-out Dell because adding capacity meant a purchase order and a drive to the data center. We did not need exotic architecture to build a nine-figure company.
The one genuinely hard call is sharding, which means splitting your data across many databases because no single one can hold it. At Stackify we ran roughly 2,000 sharded SQL Server databases because we were ingesting monitoring data at a volume no single database could handle. That is a decision you design for up front or pay dearly for later. Most products never get there, and designing for it too early is the more common and more expensive mistake. Martin Fowler makes the same case about microservices: start with the simple architecture and split it only once the complexity earns its keep.
Keep it simple and boring until you cannot.
We do not hand schema decisions to a stranger. The backend engineers we place join your standups, read your product docs, and ask the questions a senior in-house engineer would ask before they touch the data model. They average more than 7 years of experience, and most have already lived through the migration pain that teaches you restraint. The goal is an engineer who pushes back on a bad schema idea before it ships. One of our .NET teams does this for SOTA Cloud, a dental-imaging platform where the backend has to encode real clinical and regulatory rules, work you can read about in their case study.
2. API contracts falling out of sync
Your backend talks to your frontend, your mobile app, and probably a handful of other services. The agreements that govern those conversations are your API contracts. When the backend team and the rest of the team are in the same room, contracts stay in sync because people talk. When you offshore the backend through a vendor, those conversations stop happening, and the contracts fall out of sync.
The classic failure looks like this. The frontend expects a field. The backend renames it. Nobody told anybody, because the backend developer reports to a project manager who reports to an account manager who talks to your team once a week. By the time the mismatch surfaces, it is a production bug and a finger-pointing meeting.
I have seen every version of how this goes wrong, and the root cause is almost always the model itself. Most offshore collaboration fails because companies hand a pile of requirements to an outsourcing firm and expect a working product back. There is a layer of middlemen between you and the person writing the code, and contracts cannot survive that game of telephone.
We remove the middleman. The backend engineers we place are in your Slack, your repo, and your standups, with no project manager translating in between. They define API contracts with your frontend engineers directly, in the same conversation, the same way an in-house team would. When the contract needs to change, the people on both sides of it are already talking. This is plain staff augmentation, and it is the single biggest reason our backend placements hold together.
3. Infrastructure and DevOps ownership
Writing the backend code is half the job. The other half is deploying it, running it, and keeping it healthy. This is where offshore arrangements quietly fall apart, because everyone assumes someone else owns the pipeline.
The offshore team writes a service and throws it over the wall. Your in-house team gets handed something they did not build and now have to deploy and babysit. Nobody owns the infrastructure as code, the deploy process, or the monitoring. The work ships, but ownership of production is a blur, and blur is where outages live.
There is an old rule that still holds: if you have undefined work, you cannot delegate it to anyone, onshore or offshore. Infrastructure ownership is the most commonly undefined work on a backend team.
We make ownership explicit before a line of code is written. The offshore backend engineers own their own pipeline: infrastructure as code, the deploy process, and the monitoring for the services they build. They run what they build, inside your tooling and your standards, the same way your in-house engineers do. That is what AMC Theatres did with us. Their CIO, Derrick Leggett, put it plainly: “It’s a fully integrated team. It’s just some of the people happen to be living in the Philippines.” AMC runs one of the largest movie-ticketing platforms in the world, with engineers across the US, South America, India, and the Philippines, and there is no separate vendor operations layer in the middle.
4. On-call and production incidents across time zones
Here is the question that decides whether you can really offshore your backend: when the database falls over at 3am, who picks up the phone, and do they understand the system well enough to fix it?
The backend is what runs at night. Frontend bugs can wait until morning. A backend outage cannot. If the only people who understand a service are asleep on the other side of the planet, your time-zone gap stops being an advantage and becomes the reason your incident lasts six hours instead of twenty minutes. Google’s site reliability engineering team built its entire on-call practice around the idea that the responder needs deep system knowledge and a clear runbook before they ever touch the pager.
We treat the time-zone gap as a coverage decision you make on purpose, before an outage forces it on you. We staff three patterns depending on the product. The most common is a half-day overlap, where the offshore team shares four to six hours with your US workday, enough for real-time collaboration and handoffs. Some clients run a full US-hours shift for true follow-the-sun coverage. Others go async-first with a daily standup overlap. The point is that on-call is designed around the schedule you chose, with runbooks the offshore engineers wrote because they built the services. Distributed teams need real overlap and deliberate over-communication to make this work.

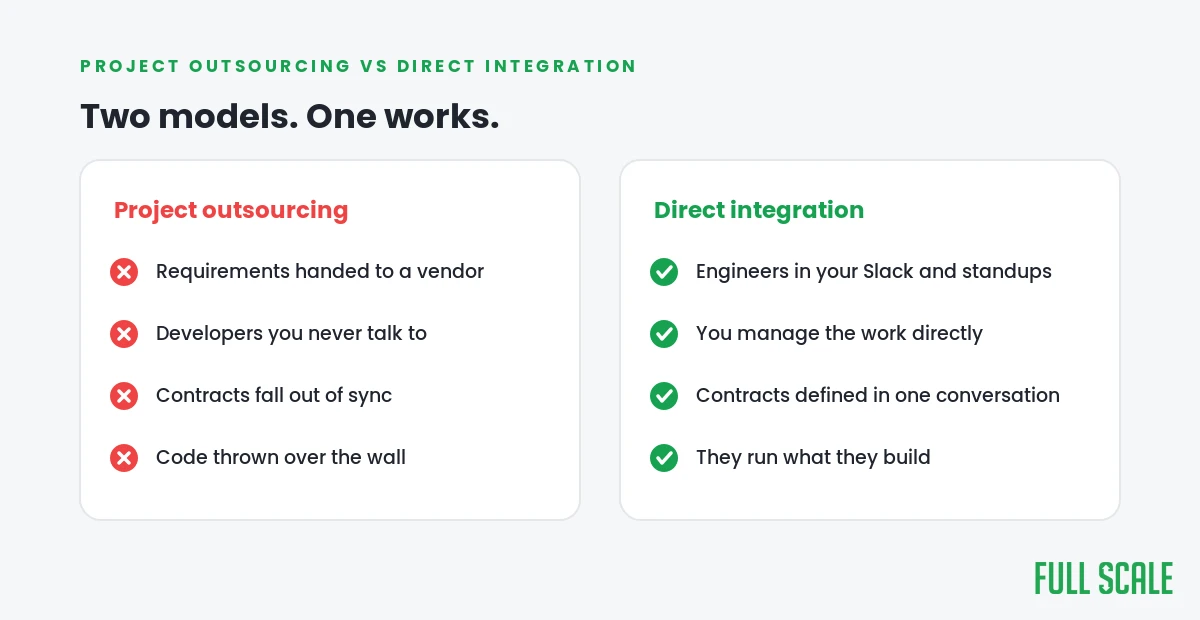
The one decision that makes all four fixable
Look closely at those four fixes and they are the same fix wearing four hats. Every one of them comes down to whether your offshore backend developers are real members of your team or a vendor on the other side of a wall.
The model that breaks is project outsourcing, where you hand requirements to a firm and get back code from developers you never meet. The model that works is direct integration, where the developers are yours in every way that matters and the staffing company handles payroll, HR, and the legal entity in the Philippines. With us, your contract is with a US company under US law, your intellectual property is assigned cleanly, and our seven-layer approach to protecting IP with offshore developers covers the rest. That structure is also why our developer retention runs at 93%, which means the engineer who learned your backend is still on your team two years from now. That retention comes from treating offshore developers like the team members they are.
This is also where I have to warn you about the cheapest path. When companies chase the lowest possible hourly rate, they end up with a freelancer who vanishes mid-sprint or a project shop that writes code held together with duct tape. I call this cheapshoring, and it does more damage on the backend than anywhere else, because the mistakes hide in the data model and the infrastructure where you cannot see them until they cost you. Cost is a fair reason to hire offshore. Cost as the only reason is the trap. The companies that have done this for years already know it: Deloitte’s 2024 Global Outsourcing Survey found the share naming cost reduction as their primary motive fell from 70% in 2020 to 34% in 2024. We pay our engineers at the top of their local market, and the quality of the work reflects it.
The deeper version of this argument, about building teams that own their outcomes, is the subject of my book Product Driven.
When offshore backend development works, and when it doesn’t
Offshore backend development is the right call when you have a stable product with a clear roadmap, documented standards, and a team that already knows how to work with remote engineers. If you can hand a new in-house hire a clean onboarding path, you can hand an offshore backend engineer the same path and get the same result. Some companies take it further and formalize the whole group as a dedicated offshore development center, with the partner carrying the infrastructure.
It is the wrong call in two situations. The first is panic mode, where you need someone tomorrow and have not defined the work. No hiring model fixes bad planning. The second is a chaotic codebase with no documentation and no standards, where the architecture changes every week. Remote engineers need even more context than local ones, and tribal knowledge does not cross an ocean. Fix that first, and then offshore.
If you want the deeper financial breakdown, our offshore development cost analysis runs the real numbers, and the broader case for offshore software development covers the model across every stack. If you need to hire offshore backend developers, our backend hiring page shows who we would put on your team.

Frequently asked questions
Is it safe to offshore backend development?
Yes, when the structure is right. Your contract should be with a company operating under US law, with clean IP assignment and enforceable confidentiality, so a dispute is handled in your legal system rather than a foreign one. At Full Scale the developers are our employees with real employment contracts, and our background checks go deeper than the US norm. The backend holds your most sensitive systems, so the legal and security structure matters more here than anywhere else.
How do you handle on-call when the backend team is offshore?
You design the coverage on purpose. We staff three patterns: a half-day overlap with your US workday, a full US-hours shift, or async-first with a daily standup overlap. The engineers who build the services also write the runbooks and carry the pager for them, so the person who handles an incident already understands the system, even at 3am.
How much does offshore backend development cost?
Senior offshore backend engineers at Full Scale run about $35 per hour, fully loaded, which includes payroll, benefits, and HR. That is roughly half the all-in cost of an equivalent US senior hire, before you account for recruiting fees and the cost of turnover. The savings compound the longer the engineer stays, which is where our 93% retention changes the math.
Which backend stacks does Full Scale support?
We place backend engineers across the major stacks, including .NET and C#, Node.js, Python, Java, and PHP. AMC Theatres and SOTA Cloud both run on .NET with our engineers embedded in their teams. We vet for your specific stack and the specific kind of work you are doing, down to the framework and the domain.
The bottom line
The backend is the highest-stakes part of your product to offshore, and that is the best argument for doing it carefully. Get the data model, the contracts, the infrastructure, and on-call right, and the location of the engineer stops mattering. Get the team model wrong, and no amount of talent will save you.


