AI Proof Interview Questions for Backend Developers

In this article
Every backend looks fine until the database gets big, a dependency gets slow, or two requests race for the same row. What a senior backend developer is really worth is seeing those moments coming and building for them before they arrive. That is exactly what most backend developer interview questions never test. They test definitions, and the day your candidate started using AI, definitions stopped telling you anything.
Look at the usual list. What is the difference between SQL and NoSQL. Explain ACID. What is REST. GET versus POST. What is a database index. What causes a deadlock. For years those were the standard backend screen, and they made sense when the only place to find the answer was inside a developer’s own head.
Not anymore. A candidate with a chat assistant in the next tab returns every one of those in seconds, and explains them well. The knowledge still matters, you cannot model data or reason about consistency without it, but it has stopped being something you can *screen* on. A clean answer no longer reveals whether the person earned it running real systems or read it off a screen a moment ago. A fluent recital used to be a fair sign of experience. AI made it a coin flip.
The work underneath moved too. AI now writes the CRUD endpoints, the boilerplate queries, the glue between services, the backend code that used to fill a morning, which pushes the scarce part of the job up a level. A senior backend developer is not worth more for typing faster. The worth is in the judgment: knowing how to model data that stays correct under load, what happens when a dependency you call is down, how to change an API without breaking the teams behind it, and whether the system should be built the way the ticket reads at all. Pure coders will be replaced by AI. Problem solvers will run technology organizations.
So the questions have to follow the job. I have spent more than twenty years building backends, including the one at Stackify, the developer-tools company I founded, that ingested billions of events a day so it could tell other engineering teams why their own systems were slow. You learn what a backend needs to survive when surviving traffic is the entire product. At Full Scale we vet every backend developer on that kind of judgment, not on syntax quizzes, before they ever join a client team. This is the question set we use to find the ones who think.
Why the database-trivia round broke
The trivia rested on one assumption: that recall stood in for skill. If you could explain ACID, you had probably lost data once and learned to respect a transaction. Recall was a shortcut to the real thing.
AI removed the shortcut. A developer who has never run a system in production can now explain database isolation levels as fluently as someone who spent a weekend tracing a corruption bug back to one. You are not measuring what you think you are measuring. The trivia is not useless to *know*. It is useless to *test*, because everyone passes and the pass tells you nothing.
What is left is the work AI cannot do for you. A model will generate an endpoint and a query in seconds. It will not tell you that the write is not idempotent and a retry will double-charge someone, that the query will collapse once the table has ten million rows, or that the service does not need to exist. Those are judgment calls, and judgment is what a senior hire is for.
Watch for the trap here. When the syntax is free, the cheapest developer who can pass the puzzle looks like the obvious hire. That is the mistake I named cheapshoring: chasing the lowest rate and treating engineers as interchangeable people who produce endpoints. It was a weak bet before and a worse one now, because the cheap part is what AI already does for free. On the backend the bill is the worst kind, because the corner you cut shows up as lost data, a midnight outage, or a number on a financial report that nobody can reconcile.
Here is the shift in backend terms:
| What the old questions tested | Why it no longer screens | What to test instead |
|---|---|---|
| Reciting ACID or normalization | AI answers it instantly; everyone passes | How they model data that stays correct under real load |
| SQL versus NoSQL definitions | Free to look up; can’t tell who has shipped | When they would actually reach for each, and why |
| Implement an algorithm on a whiteboard | AI writes it; the job is rarely this | How they break down a vague, underspecified system |
| REST verb recall | AI fills it in | How they design an API two other teams can safely build on |

What to screen backend developers for now
If recall no longer screens, what replaces it? Five things, and they line up with the five groups of questions below.
System and data architecture judgment. Whether they can defend a design and name its cost. Writing endpoints is not the same as designing a backend. Anyone who finished a tutorial can return JSON from a route. Building a backend that holds up means reasoning about how data is modeled and where consistency is enforced, about the contract other systems depend on, and about what happens when a dependency fails, because in a real system something always does. That is the knowledge a memorized definition only pretends to cover.
Problem-solving on open-ended messes. Real backend work rarely arrives as a clean spec. It arrives as “requests are slow, but only sometimes, and only for some users” or “the numbers in two systems disagree and nobody knows since when.” You want to watch how they cut an ambiguous problem into parts, and whether they ask what you are really trying to build before they start.
Scaling, reliability, and production reality. A backend that is fine in a load test can fall over the first time real traffic, real data, and a slow dependency arrive together. Senior judgment is anticipating that, the query that dies at scale, the dependency that drags your service down with it, the queue that backs up, and designing around it before a pager goes off.
API and data-integrity design. Most backends sit behind a contract other teams build on and in front of data the business cannot afford to get wrong. The strongest developers think about both: how to evolve an API without breaking callers, and how to keep data consistent when writes can fail halfway. Google’s API Design Guide is a good reference for the contract side, including idempotency, and it should be something they actually reach for.
Curiosity and working with AI. When anyone can generate an endpoint, the developer who asks “should this exist, and what problem does it solve” is worth more than the one who silently builds the ticket. The same goes for AI output: you want someone who treats it as a draft to review and steer, the way a lead reviews a junior’s pull request.
Under all five sit the three traits we screen hardest for on every stack: communication, curiosity, and courage. Communication is whether they can explain why they put a consistency boundary where they did. Curiosity is whether they are genuinely adapting to how AI changed the craft. Courage is whether they will flag a design that will lose data instead of quietly shipping it. We wrote the long version in our book on engineering leadership, and it holds up especially well on the backend, where a quiet mistake can corrupt data for months before anyone notices.
The AI-proof backend developer interview questions
The fair objection is that AI can answer these too. It can, every one will get a fluent reply in a chat window. That is fine, because the question is not what does the screening, the live format is. Push into the *reasoning* with follow-ups, ask them to walk through a real decision on a real system, throw a curveball, and a pasted answer comes apart on the second question while a genuine one gets sharper. So ask these, then keep pulling the thread.
System and data architecture judgment
1. Pick a backend system you have actually worked on and tell me one architecture decision you would make differently now. A rehearsed answer falls apart the moment you ask why, so chase it. It shows whether they look at their own systems critically and whether their opinions came from running them or from a conference talk.
2. You inherit a service where one giant table and one god-service handle everything. How do you decide what to pull apart first? Strong answers weigh risk against value and resist the urge to rewrite everything at once. The weaker instinct is a grand re-architecture with no plan to land it safely.
3. When would you not reach for microservices, a message queue, or a cache? This catches developers who add distributed-systems complexity by reflex. Knowing that each of those buys you something at a real operational cost, and that a boring monolith is often the right call, is a senior signal.
Diagnosing an open-ended problem
4. Requests are slow, but only sometimes, and only for some users. How do you find out why? This separates the developers who reach for tracing, tail latency, and the one slow dependency from the ones who stare at an average response time and guess.
5. A feature request lands as one vague sentence from the CEO. What do you do before you write any code? The answer you want is full of questions, not assumptions. The developer who clarifies the problem builds the right thing. The one who guesses builds the wrong thing fast.
6. Design a system that charges a customer’s card exactly once, even if the request is retried or the network drops in the middle of the call. Talk me through it. Listen for idempotency keys, how they make a retry safe, where they record that a charge happened, and what they do about a response that never arrives. This is the canonical backend correctness problem, and naive answers double-charge people.
Scaling, reliability, and failure
7. Your busiest endpoint slows down as the data grows. Walk me through how you would find and fix it. You want them to reason about the database first: a missing index, a query that does not scale, an N+1, a connection pool running dry. Tool fluency, slow-query logs, EXPLAIN, an APM, shows up here on its own.
8. A downstream service you depend on gets slow, and now your service is falling over too. What is happening, and how do you keep it from happening? The senior answer names the cascade and reaches for timeouts, retries with backoff, circuit breakers, and isolating the failure so one slow dependency cannot take everything down. A weaker answer just waits for the dependency to recover.
9. After a deploy, error rates climb, but only on some instances. Walk me through your investigation. You want a systematic approach: compare the bad instances to the good ones, read the traces and metrics, isolate what differs, reproduce, then ship a fix. Watch whether they reason from evidence or from a hunch.
API and data-integrity design
10. You own an API that several teams build on, and you need to change it. How do you do that without breaking them? A senior developer talks about backward compatibility, additive changes, versioning when it is truly needed, deprecation with a runway, and actually talking to the teams who depend on them. Respecting the caller is the whole point.
11. Your data is subtly inconsistent, two systems disagree and nobody is sure when it started. How does that happen, and how do you keep it from happening? This is the thesis in one question. It reveals whether they understand transactions, consistency boundaries, and the dual-write problem, and that “the code ran without an error” is not the same as “the data is correct.”
Curiosity and AI’s blind spots
12. How has AI changed the way you build backends day to day, and where do you not trust it? This is the easiest trait to test and the hardest to fake. A genuinely curious developer lights up and gets specific. The “where do you not trust it” half matters most. Veracode’s 2025 GenAI Code Security Report found that 45% of AI-generated code samples introduced a known security flaw, so a developer who reviews the output, catches the non-idempotent write and the N+1, and steers it is worth far more than one who pastes it and hopes.
The strongest version of this question is to stop asking and start watching. Hand them an endpoint an AI generated and ask what they would change before it ships. The developer who spots the missing transaction, the write that is not idempotent, the input that is never validated, and the downstream call with no error handling is showing you the exact judgment the job now rewards. The one who says “looks good” is showing you something too.
Strong answers versus red flags
These backend interview questions only work if you know what you are listening for.
Strong answers start with the data and the failure mode before the syntax. They reference real tools and real scars: a trace that found the slow dependency, a corruption bug that taught them to respect transactions, a retry that double-charged a customer once and never again. They weigh trade-offs out loud instead of declaring one right answer. And they tie technical choices back to whether the system stayed correct and stayed up.
Red flags cluster into a few habits. The candidate reaches for microservices or a queue before they understand the problem. They assume the database is infinite, the network never fails, and the data is always clean, none of which production provides. They cannot name the tools they would use to trace a slow request. They treat “it returns the right thing in testing” as “it is correct under load.” And they hand back AI output as finished work rather than a draft to review. None of those are about syntax, which is exactly the point.

How Full Scale screens backend developers
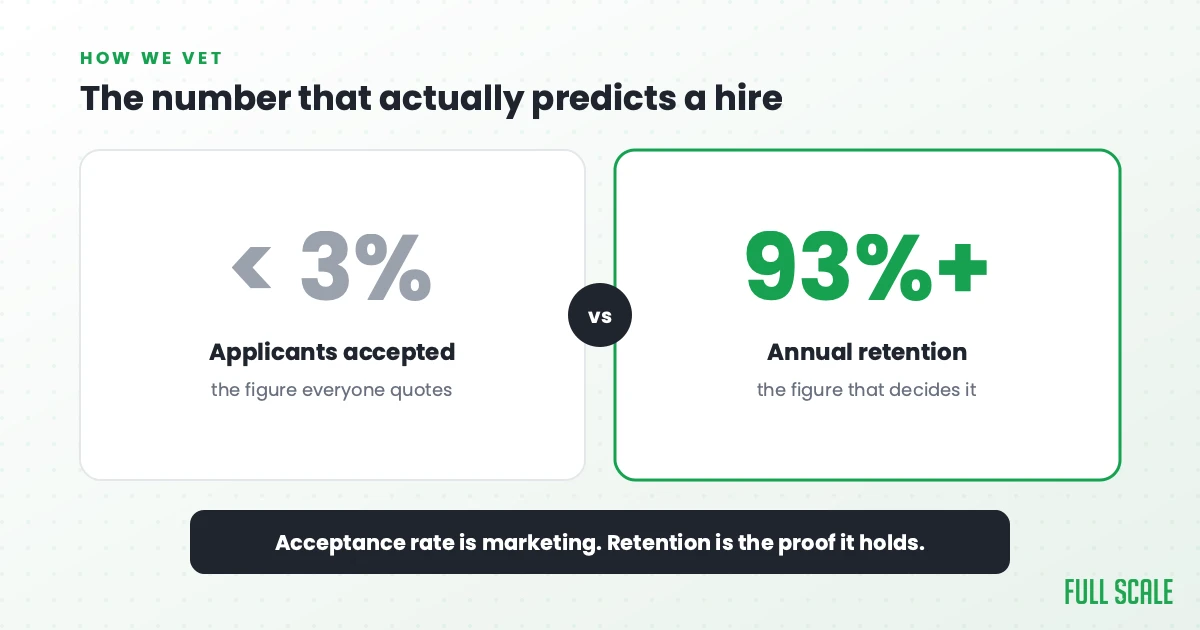
Our screening is built on exactly this, because we put our name behind every developer we place. The technical round is real architecture, data, and reliability problems, the kind a production system actually hands you, not a syntax quiz. Around it we check communication, English fluency, work ethic, and how someone operates on a distributed team, with background checks thorough enough that we have interviewed candidates’ neighbors. Fewer than 3% make it through. The full process is in our guide to interviewing a software engineer.
I am wary of that 3% number, though, because an acceptance rate is the easiest thing in this business to dress up as marketing, and it is not what makes a hire succeed. What does is whether the developer stays long enough to learn your systems and become part of the team. So the number I trust is retention, and ours runs over 93%, going back to 2018. A selective filter only matters if the people who clear it stay.
It is also why we staff integrated teams rather than run a body shop. The engineers we place at AMC Theatres sit in the standups and the roadmap conversations next to AMC’s own staff, not behind a vendor account manager. That is staff augmentation the way it should work, and it only pays off when you hire for judgment and keep people long enough for that judgment to compound.
If you are hiring for a specific stack, we go deeper in our guides to interview questions for Java, Python, .NET, and Node.js developers. You can see the full scope of our backend development services, and if you would rather skip the interviewing and start with developers who have already cleared this bar, you can hire backend developers through us directly.
It comes down to this. The facts are free now, so stop grading people on them. Grade them on the judgment that decides whether your system stays correct under load or quietly loses data until someone notices the numbers do not add up. That is what the questions above are built to surface.
Frequently asked questions
Are technical backend questions like ACID and indexing useless now?
The knowledge is not useless. A developer still needs to understand transactions, indexing, and how databases behave to debug real problems. What changed is that those topics no longer work as *screening* questions, because any candidate can recite a clean answer in seconds. Use them as a way into a real debugging story instead of as a recall test.
What should I ask a backend developer instead of coding trivia?
Ask open-ended questions that reveal judgment: how they would model data that stays correct under load, when they would not reach for microservices or a queue, how they would make a payment idempotent, and how they would keep one slow dependency from taking down the whole service. Then drill into the reasoning with follow-ups.
How do I keep a candidate from using AI on these questions?
You do not block it, you make it pointless. In a live conversation, follow-up questions surface a pasted answer almost at once. Ask the candidate to walk through a real decision from their own work, hand them an AI-written endpoint and ask what they would change before it ships, and stay on the reasoning instead of the answer.
What is the difference between a senior and a junior backend developer in the AI era?
Both can generate working backend code with AI. The senior knows which generated code to trust, where data can go wrong, what happens when a dependency fails, and whether the system should be built that way at all. The value moved from writing the code to judging it.
Want a team that has already passed these questions? Book a call and we will walk you through who we would put on your backend work.


