How to Build a DevOps Strategy That Actually Works

In this article
Stackify’s Azure bill ran past $1 million a year at one point.
That wasn’t waste. It came from real data: application logs and performance traces pouring in from thousands of customers, spread across roughly 2,000 sharded databases. We never hired a full-time DevOps person to run it. My rule was simple: if you think you need a full-time DevOps hire at a startup, your hosting is probably too complicated. Simplify it first.
That’s the whole point of a good DevOps strategy: it exists to make your team faster.
A DevOps Strategy Exists to Make Your Team Faster
On my podcast, Erica Brescia, former COO of GitHub and founder of Bitnami, put it better than most definitions I’ve read: “The key word to me is velocity.” She’d know. She joined to help run GitHub after Microsoft paid $7.5 billion for it, and the platform had more than 70 million developers building on it by the time she left.
Every practice under the DevOps umbrella, from automated deployments to infrastructure config, earns its place only if it removes friction between writing code and getting it in front of customers.
The whole point of a DevOps strategy is getting working software in front of customers faster. Every practice that doesn’t serve that just gets in the way.
The moment a practice adds a ticket, an approval gate, or a hand-off that wasn’t there before, it’s working against the goal it’s supposed to serve.
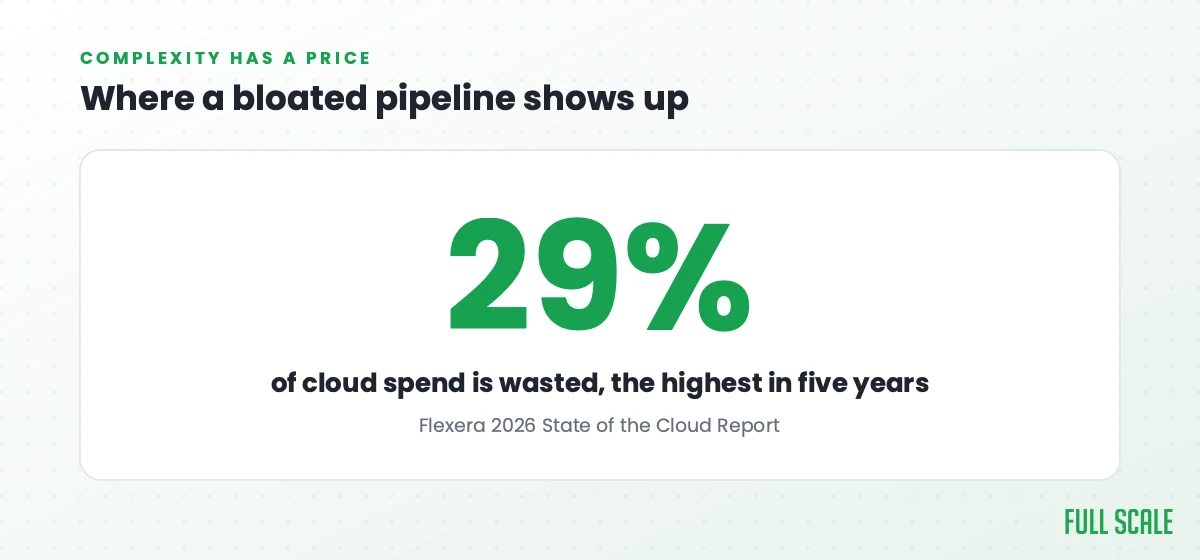
That’s also where a lot of cloud spend actually goes. Flexera’s 2026 State of the Cloud Report found that companies waste about 29% of their cloud spend, the highest that figure has been in five years. Nobody sets out to build a complicated, bloated deployment pipeline. It happens one “just add another environment” decision at a time, until it’s slower to ship than it was a year ago. That defeats the entire point of doing this in the first place.
Strip away the job title and DevOps is just a pile of practices someone has to own, plus a whole industry of tools promising to fix that for you if you’ll just buy one more subscription.

When Do You Actually Need a Dedicated DevOps Owner?
A part-time, side-of-desk version of DevOps stops being enough at three points, and every team crosses at least one of them eventually.
An acquisition forces the issue
The moment you’re preparing for a sale or a change of control, due diligence starts asking questions nobody’s had to answer carefully before: who owns the infrastructure, what happens if the person managing it leaves, how are backups actually tested. Those gaps have to belong to someone real, not “whoever has time this week.”
Compliance turns DevOps into a real function
Once you’re handling healthcare data, financial transactions, or anything that requires a real security audit, DevOps and security practices stop being optional extras. They become a function someone owns, documents, and can defend to an auditor. That owner doesn’t have to sit in your building. It has to be a specific, accountable person with the access controls and background checks to prove it, whether that’s an in-house hire or a dedicated engineer who works as a real member of your team.
Or you simply outgrow doing it part-time
Release cadence and on-call load eventually outgrow what a developer can handle as a side project, independent of compliance or an acquisition. Nobody plans this. It just happens somewhere between five engineers and thirty. A five-person team handling sensitive data can hit this earlier than headcount alone would suggest, because the trigger is what you’re responsible for, not how many people are on the payroll.
I make the same call on product owners. The threshold that matters is complexity and risk, not headcount, and every team crosses it at a different size. Most teams don’t need a dedicated product owner until the domain gets regulated or complex enough that the gap between what the customer needs and what an engineer understands is too wide to bridge part-time. DevOps follows the same rule.
I’ve written before about how a chief technology officer at a small company already wears this hat along with five other jobs. Someone might already be doing DevOps work today. The real test is whether they can keep doing it as a side project once one of those three triggers shows up.
Once you’re past that line, the fix is usually hiring a dedicated DevOps engineer whose actual job is owning it. That hire’s job description is the four practices below.

Your DevOps Roadmap: Four Practices That Actually Add Speed
Once you’ve crossed the threshold, the practical work comes down to four things. Each one should make your team faster. If it doesn’t, you’re doing it wrong.
- Infrastructure as code
- CI/CD pipeline automation
- Deployment automation and branching strategy
- Rollback strategy
Infrastructure as code
Infrastructure as code means your servers, databases, and networking are defined in version-controlled files instead of a set of clicks someone remembers how to make. I call the early-stage version of this “ClickOps,” and it’s fine at startup scale: a simple deployment pipeline configured by hand, no dedicated owner required. The problem shows up when that knowledge lives in one person’s head instead of a file everyone can read, review, and roll back.
A managed platform like Render, Vercel, or Heroku is often the right move before infrastructure as code is. It hides most of the infrastructure decisions entirely. That’s the platform-level version of the same “simplify it first” rule, the same restraint I’d apply to any scaling decision: don’t add complexity you don’t need yet.
Kubernetes and containers usually enter the picture once you outgrow that platform, because they force automation you can no longer do by hand. Once you’re at either stage, writing your setup down as code means anyone on the team can change it, test it, and ship it. That’s the same ownership mindset I write about in Product Driven: whoever touches something owns making it better, whether or not they’re the one who built it first. It’s also the cultural shift real DevOps requires: whoever builds a service helps run it, instead of throwing it over a wall to someone else.
CI/CD pipeline automation
A CI/CD pipeline is the backbone of the whole thing: it builds, tests, and deploys code without a manual hand-off between “developer wrote it” and “it’s live.” That removes the single biggest source of friction in shipping software. Every manual step in that chain is a place where speed dies waiting on a person.
And this is far simpler than it used to be. Pointing Vercel at a repository takes a couple of clicks, and connecting Azure App Service to a GitHub repo is about the same. GitHub Actions are easy to modify, and AI is genuinely good at writing and adjusting them for you. As long as you stay on platform-as-a-service and don’t run your own servers, most of the pipeline is straightforward to set up. A lot of the complexity people brace for comes from the servers themselves, so the simplest DevOps move is often owning none of them.
Deployment automation and branching strategy
Branching strategy decides how much risk piles up before it hits production. A trunk-based approach, where developers merge small changes into the main branch constantly instead of nursing long-lived feature branches, keeps that pile small by default. A bigger pile means a bigger release, and a bigger release means more time spent afterward fixing what broke.
I coined a metric for exactly that trade-off a few years back: the Pullback Ratio. An engineering leader at AMC Theatres told me their pattern years ago: a production release every Monday, two hotfixes Tuesday, one Wednesday, and if they were lucky, none by Thursday. That’s just what big, infrequent releases do to a team.
Smaller, more frequent releases shrink the pullback. A smaller changeset means fewer places for something to go wrong and a much shorter list of suspects when it does. Feature flags help here too, letting you ship code without turning it on for everyone at once. I’ve written about those separately since they deserve their own explanation. None of this works without watching what’s actually happening in production. Good observability means you find out something broke before your customers do. Bad observability is what I’ve seen at most companies: if it breaks, customers will tell you.
Rollback strategy
A real rollback plan is what turns a bad deploy into a five-minute revert instead of an all-hands fire drill. A feature flag is the easy case: flip it off and the bad code goes dark instantly. A database migration is the hard case, since you usually can’t just undo a schema change once other code depends on it, which is why the safest migrations are written to run in a way the old code can still tolerate until the rollback window closes. I’ve shipped rollback plans that were really just “hope and pray” dressed up in a runbook, and they work about as well as you’d expect. Skip this step and every other speed gain gets eaten by worry about what happens when something breaks.

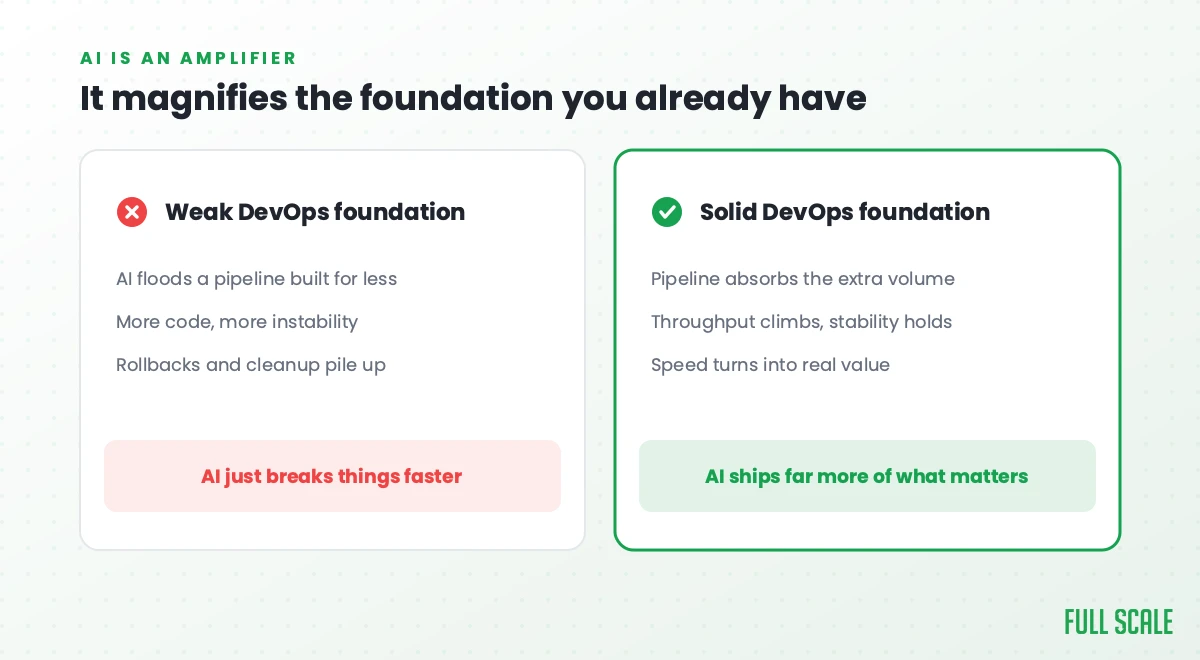
AI Amplifies Whatever DevOps Foundation You Already Have
AI writes more code, faster and cheaper than ever, and all of it lands on the same pipeline you already have. That’s the part most teams underestimate.
DORA’s 2025 research calls AI “an amplifier, magnifying an organization’s existing strengths and weaknesses.” A team with a solid DevOps foundation ships far more with AI behind it. Without that foundation, the same tools just break things faster. The same report found AI pushing delivery throughput up and stability down together, which is what happens when a flood of new code hits a pipeline that was never built for the volume.
This is exactly what the Pullback Ratio is for. If AI doubles how much your team ships but your rollback plan and CI/CD pipeline haven’t caught up, all that extra speed turns straight into extra cleanup work.
The point of AI on an engineering team was never raw output. It’s shipping more of what customers actually want. A DevOps strategy that holds the quality bar steady while AI raises the volume is what turns that speed into real value instead of a bigger mess.
How to Know Your DevOps Strategy Is Actually Working
Track the Pullback Ratio, how much cleanup work follows a release relative to its size, over time. If it’s climbing, your process has become the problem it was supposed to solve.
A few numbers worth watching alongside it: deployment frequency, and the defect escape rate (how many bugs make it to production instead of getting caught earlier). Those are two of the core metrics DORA, the longest-running research program studying software delivery performance, uses to separate teams that are actually improving from teams that just feel busier. Know where your team actually sits on both before deciding what to fix.
More often, the failure mode is too much process: approval gates, extra tickets, and ceremony that make a release feel safer without actually making it faster or more reliable. You can’t fix broken engineering with more process, and a DevOps label on the ceremony doesn’t change that. If a new step doesn’t move your Pullback Ratio or your defect escape rate, it isn’t helping.
Frequently asked questions
What is a DevOps strategy?
A DevOps strategy is a plan for how your team ships software faster without dropping the reliability, security, and compliance your business actually needs. It covers when to formalize the function with a dedicated owner and which practices, like CI/CD and infrastructure as code, actually deliver speed instead of adding process.
Do I need a dedicated DevOps engineer?
You need one once your team crosses a real threshold. That’s an acquisition or change of control, a compliance requirement like SOC 2 (a standard security audit for handling customer data), or a regulated industry. It’s also just team size and deploy frequency outgrowing a side-of-desk assignment. Below that line, a developer who understands cloud infrastructure basics is often enough.
What does a DevOps strategy example actually look like?
Stackify ran a large infrastructure footprint on a legitimately large Azure bill without a dedicated DevOps hire. The deployment process stayed simple enough for the dev team to own it. AMC Theatres’ Monday-release, Tuesday-and-Wednesday-hotfix pattern is a different kind of example: it’s exactly what a metric like the Pullback Ratio is built to catch, by showing how much cleanup a big release actually costs.
What’s the difference between DevOps and CI/CD?
CI/CD is one practice inside a DevOps strategy, not a synonym for the whole thing. CI/CD automates building, testing, and deploying code. DevOps strategy is the bigger decision: who owns that pipeline, when it needs a dedicated owner, and how you know it’s actually making your team faster.
How do I measure if my DevOps strategy is working?
Track your Pullback Ratio (how much cleanup work follows each release relative to its size), your deployment frequency, and your defect escape rate. If all three are improving, or at least holding steady while you ship more often, your DevOps strategy is doing its job.
A DevOps strategy earns its keep by getting real value to customers faster, without dropping the compliance and complexity your business genuinely needs. The moment you can’t tell if it’s helping, that’s the question to answer before you add one more tool.
If your team has crossed that threshold and needs a dedicated DevOps owner, schedule a call with Full Scale and we’ll help you figure out what that role should actually look like.


