
Last Updated on 2025-02-20
Computer vision concepts give computers the ability to function as human eyes. It grew in recent years and these advances are now being integrated into laptops, mobile phones, and other electronic devices. It is also evident in other equipment through the use of various e-commerce and software applications.
These concepts are essential for both aspiring entrepreneurs and startups who choose this field. To achieve efficient operations in computer vision, this article will discuss the basic concepts, terminologies, applications, and algorithms in computer vision.
It is not mere luck when clients and developers collaborate in solving real-life problems using computer vision. At Full Scale, we adhere to the concept of business success partnership wherein the success of our clients is our very own triumph. However, learning the concepts, transforming the concepts into code, making code into working software is a tedious process. Thus, here are the concepts of computer vision that are transformed into code.
One of the leading computer vision libraries in the market today is OpenCV. It is a cross-platform library where it can develop real-time computer-vision-applications and has C++, Python, and Java interfaces.
If you’re a software development company owner looking for remote software developers who can easily learn about OpenCV and other computer vision libraries and immediately apply them in their work, you can hire them from Full Scale – a leading offshore services provider of software development in Cebu City, Philippines.

Computer Vision Concepts: A basic guide for beginners
Image Processing
Computer vision uses image processing concepts or techniques to preprocess images and transform them into more appropriate data for further analysis. Image processing is usually the first step in most computer vision systems.
Most applications that use computer vision rely mostly on image processing algorithms.
Common image processing techniques:
- Exposure correction
- Reduction of image noise
- Straighten or rotation of image
- Increase sharpness
A lot of techniques in image processing are being utilized in computer vision like linear and non-linear filtering, the Fourier transform, image pyramids and wavelets, geometric transformations, and global optimization.
Here are some simple filtering techniques in image processing. Image filtering allows modification and clarification of an image to extract the needed data. Here, OpenCV and Python are used to demonstrate linear and non-linear filtering.
Linear Filtering
Linear filtering is a neighborhood operation, which means that the output of a pixel’s value is decided by the weighted sum of the values of the input pixels.
Box filter
An example of linear filtering is the box filter which is easy to implement.
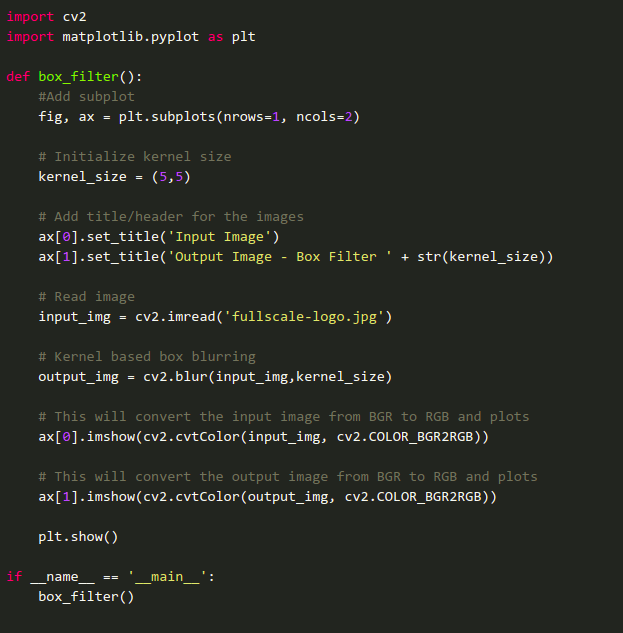
Sample code to implement the box filter:
Output of the code:
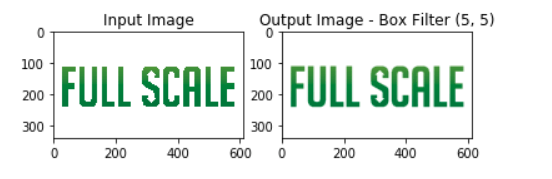
This implementation uses a kernel-based box blurring technique, which is a built-in function in OpenCV. Applying the box filter to an image would result in a blurred image. In this implementation, we can set the size of the kernel – a fixed-size array of numbers that has an anchor that is usually found at the center of the array.

Increasing the kernel size would result in a more blurred image because this implementation averages out the small neighborhood’s peak values where the kernel is applied.
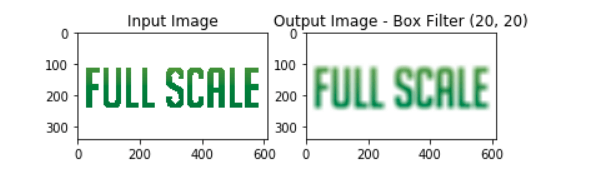
Initializing a kernel size with a smaller value would have no noticeable effect on an image because the kernel size is smaller than the actual size of the image.

Blurring through Gaussian Filter
This is the most common technique for blurring or smoothing an image. This filter improves the resulting pixel found at the center and slowly minimizes the effects as pixels move away from the center. This filter can also help in removing noise in an image. For comparison, the box filter does not return a smooth blur on a photo with an object that has hard edges, while the Gaussian filter can improve this problem by making the edges around the object smoother.
OpenCV has a built-in function called GaussianBlur() that blurs an image using the Gaussian filter.
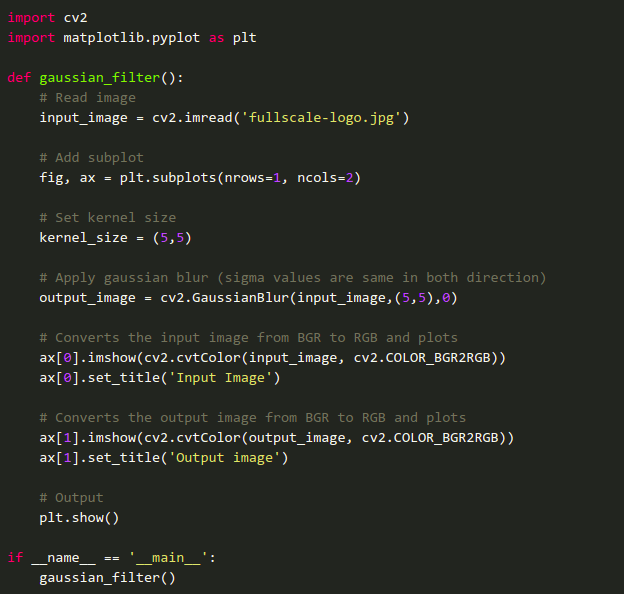
Sample code for Gaussian Filter:
Output of the code:
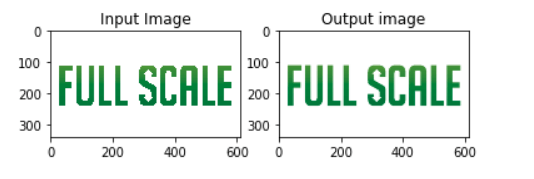
In this implementation, the kernel size is set to 5,5. The result is a blurred photo where strong edges are removed. We can see that this filter executed a more efficient blurring effect on the image than the box filter.
Non-Linear Filtering
Linear filtering is easy to use and implement. In some cases, this method is enough to get the necessary output. However, an increase in performance can be obtained through non-linear filtering. Through non-linear filtering, we can have more control and achieve better results when we encounter a more complex computer vision task.
Median Filtering
Median filter is an example of a non-linear filtering technique. This technique is commonly used for minimizing the noise in an image. It operates by inspecting the image pixel by pixel and taking the place of each pixel’s value with the value of the neighboring pixel median.
Sample code for median filtering:
In this implementation, we used the OpenCV built-in function cv2.medianBlur() and passed a 50% noise to the input image to see the effects of applying this filter.
Output of the code:
Full Scale image-5
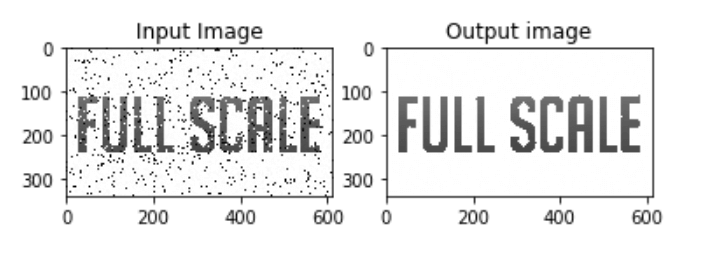
In the above image, we can see that the noise from the input image was reduced. This proves that the median filtering technique is very effective in preventing noise (specifically salt and pepper noise) in an image.
Our developers offer revolutionary techniques that will change the negative perception of unresolved issues concerning computer vision. Our concern for our clients is beyond partnership, we offer constant consultation, sound advice, help, and build solutions using the core concepts of computer vision as our developers gain knowledge and our client’s businesses thrive and gain revenue in the long run.
Feature detection and matching
When it comes to concepts in computer vision, feature detection and matching are some of the essential techniques in many computer vision applications. Some tasks involved in this technique are recognition, 3D reconstruction, structure-from-motion, image retrieval, object detection, and many more.
This technique is usually divided into three tasks which are detection, description, and matching. In the detection task, points that are easy to notice or match are recognized in each image. In the description task, the aspect that surrounds each feature point is depicted in a way that it is unchanged in events like illumination, translation, scale, and in-plane rotation. In matching, for similar features to be classified, descriptors are being compared across images.
Some techniques in detecting and matching features are:
- Lucas-Kanade
- Harris
- Shi-Tomasi
- SUSAN (smallest univalue segment assimilating nucleus)
- MSER (maximally stable extremal regions)
- SIFT (scale invariant feature transform)
- HOG (histogram of oriented gradients)
- FAST (features from accelerated segment test)
- SURF (speeded-up robust features)
Let’s demonstrate some of the popular feature detection and matching techniques:
Scale Invariant Feature Transform (SIFT)
SIFT solves the problem of detecting the corners of an object even if it is scaled. Steps to implement this algorithm:
- Scale space extrema detection – This step will identify the locations and scales that can still be recognized from different angles or views of the same object in an image.
- Keypoint localization – When possible key points are located, they would be refined to get accurate results. This would result in the elimination of points that are low in contrast or points that have edges that are deficiently localized.
- Orientation assignment – In this step, a consistent orientation is assigned to each key point to attain invariance when the image is being rotated.
- Keypoint matching – In this step, the key points between images are now linked to recognizing their nearest neighbors.
Sample code for implementing the SIFT algorithm:
The above code is a simple implementation of detecting and drawing key points in OpenCV.
OpenCV can find the key points in an image using the function sift.detect(). Also, openCV can draw these key points to better visualize these points. The cv2.drawKeyPoints() function makes better visualization of these key points by drawing small circles on their locations.
This is the resulting image of the code:

As we can see in the resulting image, the output shows the located key points of the inputted image.
OpenCV also provides us the function to calculate the descriptor. If we already found the key points of the image, we can utilize the function sift.compute() to compute the descriptor. If key points are not located, we can use the sift.detectAndCompute() to find the key points and compute the descriptor in one function.
Speeded-Up Robust Features (SURF)
SURF was introduced to as a speed-up version of SIFT. Though SIFT can detect and describe key points of an object in an image, still this algorithm is slow.
The implementation of the SURF algorithm using OpenCV is the same as implementing the SIFT algorithm. First, you need to create a SURF object using the function cv2.xfeatures2d.SURF_create(). You can also specify parameters to this function. We can detect keypoints using SURF.detect(), compute descriptor using SURF.compute and combine these two functions using SURF.detectAndCompute().
Sample for implementing the SURF algorithm in OpenCV:
Original image:

Output of the code:
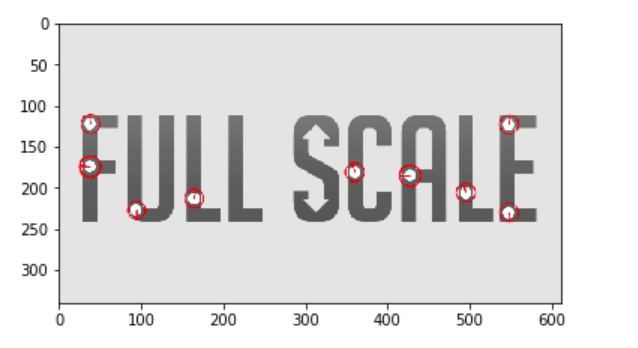
We can see that SURF detects the white blobs in the Full Scale logo, which somehow works like a blob detector. This technique can help in detecting some impurities of an image.
Oriented FAST and rotated BRIEF (ORB)
This algorithm is a great possible substitute for SIFT and SURF, mainly because it performs better in computation and matching. It is a combination of fast keypoint detector and brief descriptor, which contains a lot of alterations to improve performance. It is also a great alternative in terms of cost because the SIFT and SURF algorithms are patented, which means that you need to buy them for their utilization.
Sample code for implementing the ORB algorithm:
The implementation is the same as the first two algorithms that we implemented. We need to initialize an ORB object using cv2.ORB_create(). Then we can detect key points and compute the descriptor using the functions ORB.detect() and ORB.compute().
Output of the code:

Segmentation
In computer vision, segmentation is the process of extracting pixels in an image that is related. Segmentation algorithms usually take an image and produce a group of contours (the boundary of an object that has well-defined edges in an image) or a mask where a set of related pixels are assigned to a unique color value to identify it.
Popular image segmentation techniques:
- Active contours
- Level sets
- Graph-based merging
- Mean Shift
- Texture and intervening contour-based normalized cuts
Semantic Segmentation
The purpose of semantic segmentation is to categorize every pixel of an image to a certain class or label. In semantic segmentation, we can see what is the class of a pixel by simply looking directly at the color, but one downside of this is that we cannot identify if two colored masks belong to a certain object.
Instance Segmentation
In semantic segmentation, the only thing that matters to us is the class of each pixel. This would somehow lead to a problem that we cannot identify if that class belongs to the same object or not. Semantic segmentation cannot identify if two objects in an image are separate entities. So to solve this problem, instance segmentation was created. This segmentation can identify two different objects of the same class. For example, if an image has two sheep in it, the sheep will be detected and masked with different colors to differentiate what instance of a class they belong to.
Panoptic Segmentation
Panoptic segmentation is basically a union of semantic and instance segmentation. In panoptic segmentation, every pixel is classified by a certain class and those pixels that have several instances of a class are also determined. For example, if an image has two cars, these cars will be masked with different colors. These colors represent the same class — car — but point to different instances of a certain class.
Recognition
Recognition is one of the toughest challenges in the concepts in computer vision. Why is recognition hard? For the human eyes, recognizing an object’s features or attributes would be very easy. Humans can recognize multiple objects with very small effort. However, this does not apply to a machine. It would be very hard for a machine to recognize or detect an object because these objects vary. They vary in terms of viewpoints, sizes, or scales. Though these things are still challenges faced by most computer vision systems, they are still making advancements or approaches for solving these daunting tasks.
Object Recognition
Object recognition is used for indicating an object in an image or video. This is a product of machine learning and deep learning algorithms. Object recognition tries to acquire this innate human ability, which is to understand certain features or visual detail of an image.
How does it work? There’s a lot of ways to perform object recognition. The most popular way of dealing with this is through machine learning and deep learning. These two algorithms are the same, but they differ in implementation.
Object recognition through deep learning can be achieved through training models or through utilizing pre-trained deep learning models. To train models from scratch, the first thing you need to do is to collect a large number of datasets. Then you need to design a certain architecture that will be used for creating the model.
Object recognition using deep learning may produce detailed and accurate results, but this technique is very tedious because you need to collect a large number of data.
Just like in deep learning, object recognition through machine learning offers a variety of approaches. Some common machine learning approaches are:
- HOG feature extraction
- Bag of words model
- Viola-Jones algorithm
Object Detection
Object detection in computer vision refers to the ability of machines to pinpoint the location of an object in an image or video. A lot of companies have been using object detection techniques in their system. They use it for face detection, web images, and security purposes.
What is the difference between object recognition and object detection? Object recognition is the process of rendering an image while object detection answers the location of an object in the image.
Object detection uses an object’s feature for classifying its class. For example, when looking for circles in an image, the machine will detect any round object. To recognize any instances of an object in a class, this algorithm uses learning techniques and extracted features of an image.

Hire software developers from Full Scale
We would like to duplicate the success of the masters – Matt DeCoursey and Matt Watson into your business. Through our Guided Development system, we’ll provide you with a dedicated team of software developers who will work directly with you daily, and that you can directly guide their development efforts.
The crucial point for startups that ventures with computer vision are the realistic blow of competition. To compete, every business owner needs to deal with the huge expense of resources and the technical requirements, the limitation of the concepts mentioned, and the scarcity of software developers who are equipped with the knowledge on computer vision.
Our developers are proficient in C++, Python, and Java – the major programming languages that support open-source computer vision libraries. Contact us now to know more about how we can help your business grow and expand through our continued support and dedicated services!

Matt Watson is a serial tech entrepreneur who has started four companies and had a nine-figure exit. He was the founder and CTO of VinSolutions, the #1 CRM software used in today’s automotive industry. He has over twenty years of experience working as a tech CTO and building cutting-edge SaaS solutions.
As the CEO of Full Scale, he has helped over 100 tech companies build their software services and development teams. Full Scale specializes in helping tech companies grow by augmenting their in-house teams with software development talent from the Philippines.
Matt hosts Startup Hustle, a top podcast about entrepreneurship with over 6 million downloads. He has a wealth of knowledge about startups and business from his personal experience and from interviewing hundreds of other entrepreneurs.


