Software Development Methodologies: The Top 10 and Which Ones Actually Matter

In this article
- What a software development methodology actually is
- The top 10 software development methodologies (and what each is really for)
- How to actually choose a methodology
- Why the methodology matters less than you think
- What methodology means when AI writes the code
- Frequently asked questions
- The methodology serves the product, not the other way around
Walk into any engineering org and you’ll find people ready to argue about methodology like it’s a religion. The Scrum believers spar with the Kanban crowd, the Agile purists roll their eyes at the team still running a Waterfall plan they won’t admit to, and everyone is sure the right framework is the only thing between them and great software. Agile wins that argument for a reason, though it pays to know which benefits of the agile methodology still matter in the AI era. Whichever methodology you pick, it runs on top of the seven phases of the SDLC.
I’ve run engineering teams for more than 20 years. I co-founded VinSolutions, the number-one CRM in automotive, and sold it for $147 million. I built Stackify. Now I’m CEO of Full Scale, where we run a team of 350+ engineers across dozens of client products. I’ve shipped software under Waterfall, Agile, Scrum, and Kanban, and I’ve watched teams succeed and fail under every one of them.
Here’s what 20 years taught me.
The methodology you pick matters far less than whether your team knows what they’re building and why.
That doesn’t make methodology useless. It makes it a tool, not a strategy. So let’s do two things: walk the top 10 software development methodologies and what each one is actually good for, then talk about the part that really decides whether your project lives or dies.
What a software development methodology actually is
A software development methodology is the approach your team uses to plan, build, test, and ship software. It sets how you break work into pieces, how you handle change, and how often you release. You’ll also see them called software development methods, systems development methodologies, application development methodologies, or just different development approaches. They all describe the same thing. Some plan everything up front and resist change. Others assume the plan will shift as you learn. The rest of this post walks the main ones and where each fits.
Methodologies are often confused with the software development life cycle (SDLC). The SDLC is the set of stages every software project moves through: requirements, design, build, test, deploy, and maintain. A methodology is how your team moves through those stages. Waterfall runs the SDLC as a one-way sequence. Agile runs it in iterative loops, revisiting earlier stages in every sprint. DevOps folds deploy and maintain into the development cycle itself. The same stages apply regardless of which methodology you pick; the methodology decides whether you run them once or many times over.

The top 10 software development methodologies (and what each is really for)
These are in no particular order. Each one solves a real problem. The trick is matching the method to the kind of work in front of you.
1. Waterfall
Waterfall is the original, linear approach. You move through fixed phases in order: requirements, design, build, test, release, maintain. You finish one phase before the next begins. It gives you heavy documentation and a predictable plan, and it struggles the moment requirements change, which on most software projects is right away.
I rarely reach for Waterfall on a product. It still makes sense when the requirements genuinely won’t move and a mistake is expensive to undo, like an enterprise resource planning (ERP) rollout or a build with hard compliance gates.
Best for: fixed-scope projects with stable requirements and strict sign-off, like an ERP system or a regulated build.
2. Agile
Agile isn’t a single method. It’s a family of approaches built on a simple idea from the Agile Manifesto: work in small increments, get feedback often, and expect the plan to change. Scrum, Kanban, and Extreme Programming all live under it.
Agile is the default for most product work, for good reason. When you don’t know exactly what the right product is yet (and you usually don’t), shipping in small slices and adjusting beats guessing the whole thing up front. The cost is that it leans on real customer involvement, and it can get messy on big programs without strong leadership. It also got turned into an assembly line in a lot of teams: Scrum Masters, product owners, product managers, QA gates, and along the way developers got stripped down to engineers who execute tickets rather than own outcomes. The Agile mindset is worth keeping; the bureaucracy it accumulated is not. For the full breakdown of how Agile stacks up against Waterfall and when each one wins, the comparison post covers that decision in depth.
Best for: product development where requirements evolve and you want frequent feedback, like an e-commerce app you grow feature by feature.
3. Scrum
Scrum is the most popular flavor of Agile. Work happens in fixed-length sprints, usually two weeks, with clear roles, daily standups, sprint planning, and a review at the end. A Scrum Master runs the ceremonies and clears blockers, and keeping those meetings tight and useful is most of what a Scrum Master does.
Scrum works because the cadence forces a team to ship something real every couple of weeks and to talk to each other every day. The failure mode is cargo-culting the ceremonies. I’ve seen teams hold every meeting on the calendar and still have no idea why they’re building what’s in the sprint.
Best for: teams that benefit from a steady rhythm and clear roles, like a mobile app shipping new features in two-week sprints. For the full decision on the full Scrum vs Kanban choice and when each one fits your team, the comparison goes deeper on what actually drives that call.
4. Kanban
Kanban is a visual method. You put work on a board, limit how much is in progress at once, and pull the next item when you have capacity. There are no fixed sprints. Work just flows.
I like Kanban for support, maintenance, and a steady stream of unrelated requests, where forcing everything into a two-week sprint feels artificial. The weakness is that without sprint pressure, planning can get loose and priorities can pile up faster than the team clears them.
Best for: continuous, unpredictable work like bug fixes, support, and ongoing tweaks to a live product.
5. Lean
Lean software development comes from manufacturing. The whole idea is to cut waste and protect the work that actually creates value for the customer. Anything that doesn’t, you stop doing. It pairs naturally with Agile.
Lean is less a set of ceremonies and more a mindset, and it’s the one I keep coming back to. Most teams aren’t slow because of their process. They’re slow because they’re busy building things that never mattered, which is the whole logic behind a tight minimum viable product. We’ll come back to this, because it’s what this whole post is actually about.
Best for: startups and small teams testing ideas fast, where every hour spent on the wrong thing is an hour you don’t have.
6. DevOps
DevOps brings development and operations together so you can release often and safely. It runs on automation: continuous integration and continuous delivery (CI/CD), automated testing, and infrastructure you can stand up with code.
DevOps is less about how you plan work and more about how you ship it, so most teams run it alongside Agile rather than instead of it. The investment is real, because you need the tooling and the culture, but the payoff is shipping daily without holding your breath.
Best for: cloud and SaaS products that need frequent, reliable releases.
7. Extreme Programming (XP)
Extreme Programming (XP) is a disciplined Agile approach built around engineering practices: pair programming, continuous testing, and constant refactoring. The goal is very high code quality through tight feedback.
XP produces excellent code when a team has the discipline for it. That’s also the catch. It asks a lot, and not every team will pair-program and test-first day after day. When it sticks, the quality is hard to beat, and it leans heavily on test-driven development.
Best for: small, senior teams on quality-critical software.
8. Spiral
The Spiral model is built around risk. You move through repeated cycles of planning, risk analysis, building, and customer review, and you tackle the riskiest unknowns first. It blends iterative work with heavy up-front analysis.
Spiral fits big, expensive, high-stakes projects where a missed risk is a disaster, like a medical device. The cost is time. All those cycles and risk reviews are slow, and they’re overkill for a normal app.
Best for: large, complex, high-risk builds where finding problems early is worth the extra time.
9. Feature-Driven Development (FDD)
Feature-Driven Development (FDD) organizes the whole project around a list of small, client-valued features. You model the domain, build a feature list, then design and build feature by feature, tracking progress against that list.
FDD shines on larger projects with many features and several teams, where a shared feature list keeps everyone aligned. It needs solid up-front modeling and experienced people to run it, so it’s heavy for a small build.
Best for: large applications with lots of distinct features, like an online learning platform.
10. Rapid Application Development (RAD)
Rapid Application Development (RAD) trades heavy planning for speed. You build prototypes fast, put them in front of users, and refine quickly based on what you learn.
RAD is great when you need something usable in front of people quickly and you’re willing to clean up later. The risk is exactly that. Skip the cleanup and you’ve traded long-term maintainability for short-term speed.
Best for: time-boxed builds where speed beats polish, like a prototype or a campaign app.

How to actually choose a methodology
Most “how to choose” advice hands you a long checklist. You really only need to weigh five things.
Project requirements and complexity. If the requirements are stable and you can define them up front, a plan-driven method like Waterfall can work. If they’ll change as you learn, which is most products, go Agile.
Team size and experience. Smaller, senior teams move fast with light process like Scrum or Kanban. Bigger programs need more structure to keep everyone aligned, which is really a question of team structure as much as methodology.
Customer involvement. If you can get real, frequent feedback from users or stakeholders, Agile pays off. If you can’t, a method that leans on constant feedback will stall.
Time constraints. A hard deadline with fixed scope favors a planned approach. An uncertain timeline with shifting priorities favors an iterative one. Either way, your choice shapes how you handle project timeline estimation.
Risk tolerance. High-stakes work where failure is expensive justifies the heavier, risk-first methods like Spiral. Most product work doesn’t need that weight.
Here’s the part nobody tells you, though.
Pick the one that fits the work, then stop fussing over it. The teams I’ve seen waste the most time are the ones that keep re-litigating their process instead of building.
The honest version of most high-performing teams is a hybrid, and it runs on a real structural insight: Agile across the arc of the project, but closer to waterfall at the task level. Developers pick up a scoped piece of work, figure it out, and move to the next one. That is not a failure of Agile discipline. It is how the work actually happens, and running both levels deliberately gives you the delivery cadence of Agile and the day-to-day clarity of a waterfall loop.

Why the methodology matters less than you think
I learned this the hard way.
Years ago at Stackify, where we built monitoring and logging tools for developers, my team ran a clean process. We had a solid roadmap, sprints went out on schedule, and we shipped new features constantly. By every methodology scorecard, we were doing it right. The product still didn’t land, because we never stopped to ask whether the work actually mattered to the customer. We were executing beautifully on the wrong thing.
No methodology catches that for you. A perfect Scrum board full of the wrong features still ships the wrong product, just on time.
Process tells your team how to build, but it can’t tell them what to build or why. That decision needs its own discipline, which is why I lean on a prioritization framework like RICE to make the team weigh value against effort.
That gap is where most projects actually fail, and it’s the reason I wrote Product Driven. The teams that win aren’t the ones with the cleanest ceremonies. They’re the ones where every engineer understands the customer and the problem well enough to push back on a bad idea. Methodology is scaffolding. It holds the work up while the team builds the thing that actually matters.
This isn’t a knock on process. Good process removes friction so your team can do what counts. But when leaders treat the framework as the answer, they stop looking at the thing that’s really slowing them down, which is almost always unclear priorities and a team that doesn’t know why they’re building what’s on the board.
There’s a real exception worth naming. On safety-critical or regulated work, like a medical device or a payments system under audit, the process rigor is part of the safety net itself, and you can’t shortcut it. For most product teams, though, that’s not the situation they’re in, and the framework is rarely what’s holding them back.
What methodology means when AI writes the code
This matters more now, not less, because the mechanical part of the job is disappearing.
In April 2026, Google CEO Sundar Pichai said 75% of the company’s new code is now AI-generated, with every line still reviewed and approved by an engineer. When AI writes most of the code, the ceremony around writing code matters even less. The bottleneck moves up, to deciding what to build and judging whether the output is any good.
The research points the same way. The 2025 DORA report found that AI amplifies whatever’s already there. Strong teams get faster and better, weak teams just ship their problems quicker. A new methodology works the same way. It speeds up whatever you already are, and it won’t fix a broken team. Developers feel the pressure too. In the 2025 Stack Overflow survey, 84% of developers use or plan to use AI tools, but about 46% don’t trust the accuracy of what it gives them. The human still has to judge the work, which is why the core engineering principles matter more than ever when AI writes most of the code.
So the skills that decide success are the human ones. I tell our engineers it comes down to three things: communication, curiosity, and courage. The job is now about understanding problems and working with people, so communication carries more weight than it used to. The tools change every few months, so the engineers who stay curious are the ones who keep up. And courage matters because someone has to be willing to say the thing on the board is wrong before the team builds it.
None of that lives in your methodology, and the bigger picture is that the whole software development process is changing underneath all of it. Pick a sensible method, run it well, and put your real attention on the part that always mattered. Whether Agile survives this shift and what actually changes is a question a lot of people are asking in 2026, and whether Agile is even still worth it has a direct answer.

Frequently asked questions
What is a software development methodology? It’s the approach a team uses to plan, build, test, and ship software. It defines how work is broken up, how changes are handled, and how often you release. Common examples are Agile, Scrum, Kanban, Waterfall, and DevOps.
What are the main types of software development methodologies? They fall into two broad camps. Plan-driven methods like Waterfall and Spiral define everything up front and move through fixed phases. Agile methods like Scrum, Kanban, and XP work in small increments and expect the plan to change. Most modern product teams use an Agile method, often paired with DevOps for releases.
Agile vs Waterfall, which is better? Neither is better in the abstract. Waterfall fits stable, well-defined projects where the scope won’t move. Agile fits product work where requirements evolve and you want frequent feedback. Most software today is the second kind, which is why Agile is the default.
What’s the best software development methodology? The one that fits your work, your team, and your customer. There’s no universal winner. And once you’ve picked a reasonable fit, the bigger driver of success isn’t the methodology at all. It’s whether your team has the clarity to build the right thing.
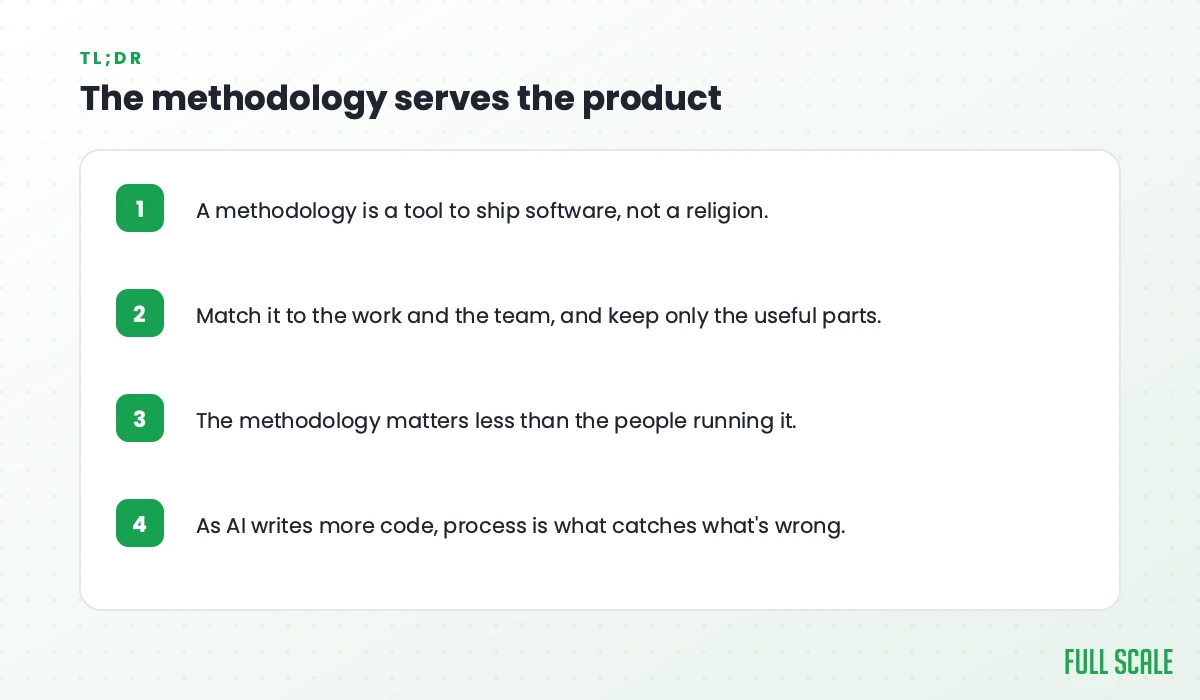
The methodology serves the product, not the other way around
At Full Scale, our engineers join your team and run your process, whatever it is, whether that’s Agile, Scrum, your own board, or your standups. We’ve done it across time zones with distributed teams, and the lesson holds every time: we care less about which framework you use and more about whether the people building your product understand it well enough to build the right thing.
That’s the part worth getting right. If you want a team of senior engineers who think that way, let’s talk about building yours.