Building Fault-Tolerant Distributed Team Software Architecture: A Technical Deep Dive
Distributed team software architecture enables development teams across multiple time zones to build fault-tolerant applications. It uses asynchronous patterns, automated deployments, and timezone-aware monitoring to transform traditional synchronous development.
Building reliable systems with distributed teams requires specialized architectural patterns. Our client achieved 99.99% uptime with developers across four time zones using a distributed team software architecture.
This guide reveals the exact technical patterns that transformed their system.
The Distributed Team Architecture Challenge
Traditional software architectures fail when teams work across multiple timezones. Synchronous communication creates bottlenecks that cascade into system failures. Knowledge silos form naturally when developers can’t collaborate in real-time.
Why Traditional Patterns Break Down
Our client initially struggled with 3-4 hours of downtime monthly. Their monolithic architecture required synchronized deployments across the US, Philippines, Eastern Europe, and India teams. Each deployment became a coordination nightmare requiring all teams to be online simultaneously.
The following diagram shows how deployment failures cascaded across time zones:
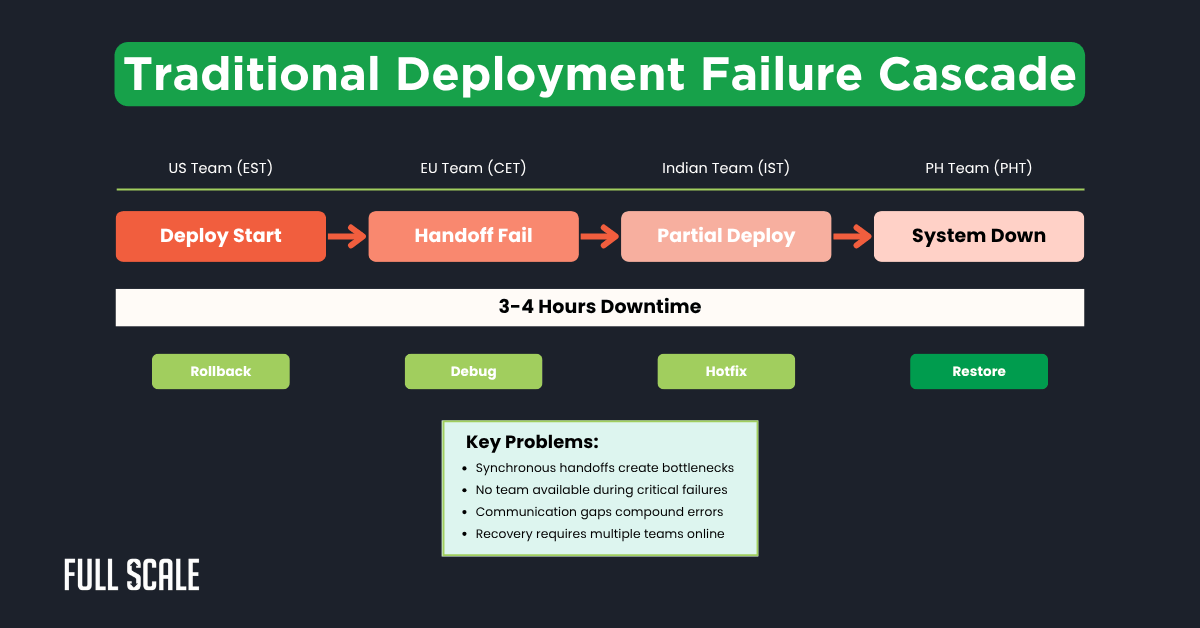
This cascade effect highlighted three critical architectural flaws. First, synchronous deployments created single points of failure. Second, no team owned complete system knowledge across all time zones.
Core Architectural Patterns for Distributed Team Software Architecture
Event-driven architecture transforms how distributed engineering teams collaborate. Instead of waiting for responses, teams publish events that others process asynchronously. This pattern eliminates timezone dependencies while maintaining system coherence.
Pattern 1: Event-Driven Architecture for Async Collaboration
Event buses enable fault-tolerant systems for distributed teams to build together. Each team publishes deployment events without waiting for acknowledgment. The receiving team processes events during their working hours.
class DistributedEventBus:
def __init__(self, redis_client):
self.redis = redis_client
self.handlers = defaultdict(list)
self.timezone_routing = {}
def publish(self, event_type, payload, timezone_context):
event = {
'type': event_type,
'payload': payload,
'timezone': timezone_context,
'timestamp': datetime.utcnow().isoformat(),
'retry_count': 0
}
# Route to appropriate team queue
target_queue = self.get_team_queue(timezone_context)
self.redis.lpush(target_queue, json.dumps(event))
# Set TTL for event expiration
self.redis.expire(target_queue, 86400) # 24 hours
def get_team_queue(self, timezone):
timezone_to_queue = {
'US/Eastern': 'events:us-team',
'Europe/Berlin': 'events:eu-team',
'Asia/Kolkata': 'events:india-team',
'Asia/Manila': 'events:ph-team'
}
return timezone_to_queue.get(timezone, 'events:global')
Distributed team software architecture relies heavily on asynchronous messaging patterns. This approach ensures remote team system reliability even when teams work independently. Our Philippines team deploys features while the US team sleeps peacefully.
Pattern 2: Circuit Breaker with Timezone-Aware Fallbacks
Circuit breakers prevent cascade failures in offshore team system architecture. When one team’s service fails, the system automatically routes to another timezone’s healthy instance. This approach ensures high availability of remote development regardless of team availability.
The following interactive tool calculates optimal circuit breaker thresholds based on your team distribution:
Circuit Breaker Threshold CalculatorCircuit Breaker Configuration Calculator
This calculator helps teams configure circuit breakers for their specific setup. Teams with more timezone coverage can use aggressive thresholds. Teams with less overlap need conservative settings to prevent false positives.
Key benefits of circuit breaker implementation:
- Prevents cascade failures across regions
- Automatically routes to healthy instances
- Reduces manual intervention requirements
- Maintains service availability during regional outages
Implementing a distributed team software architecture requires careful threshold tuning. Circuit breakers ensure the fault tolerance offshore developers need for independent operation. Our team maintains system stability even during US infrastructure issues.
Pattern 3: Distributed Tracing for Cross-Timezone Debugging
Distributed tracing becomes critical when debugging multi-timezone engineering teams’ deployments. Each trace includes team ownership metadata and timezone context. This visibility enables any team to diagnose issues without waiting for the original developers.
class DistributedTracer {
constructor(serviceName, teamTimezone) {
this.serviceName = serviceName;
this.teamTimezone = teamTimezone;
this.tracer = initTracer(serviceName);
}
startSpan(operationName, parentSpan = null) {
const span = this.tracer.startSpan(operationName, {
childOf: parentSpan,
tags: {
'team.timezone': this.teamTimezone,
'team.region': this.getRegion(this.teamTimezone),
'deployment.version': process.env.VERSION,
'service.owner': this.getTeamOwner()
}
});
// Add baggage for cross-service propagation
span.setBaggageItem('origin.timezone', this.teamTimezone);
span.setBaggageItem('trace.priority', this.calculatePriority());
return span;
}
getRegion(timezone) {
const regionMap = {
'US/Eastern': 'americas',
'Europe/Berlin': 'emea',
'Asia/Kolkata': 'apac',
'Asia/Manila': 'apac'
};
return regionMap[timezone] || 'global';
}
}
Deployment Strategies for Distributed Team Software Architecture
Remote team deployment strategies must account for timezone handoffs and async coordination. Blue-green deployments with progressive rollouts eliminate the need for synchronized releases. Each team deploys independently while maintaining system stability.
Blue-Green Deployments with Rolling Team Handoffs
This deployment pattern enables distributed development patterns that work across time zones. Teams deploy to their “blue” environment during working hours. The system automatically promotes successful deployments when the next team comes online.
The following visualization shows how deployments flow across time zones:
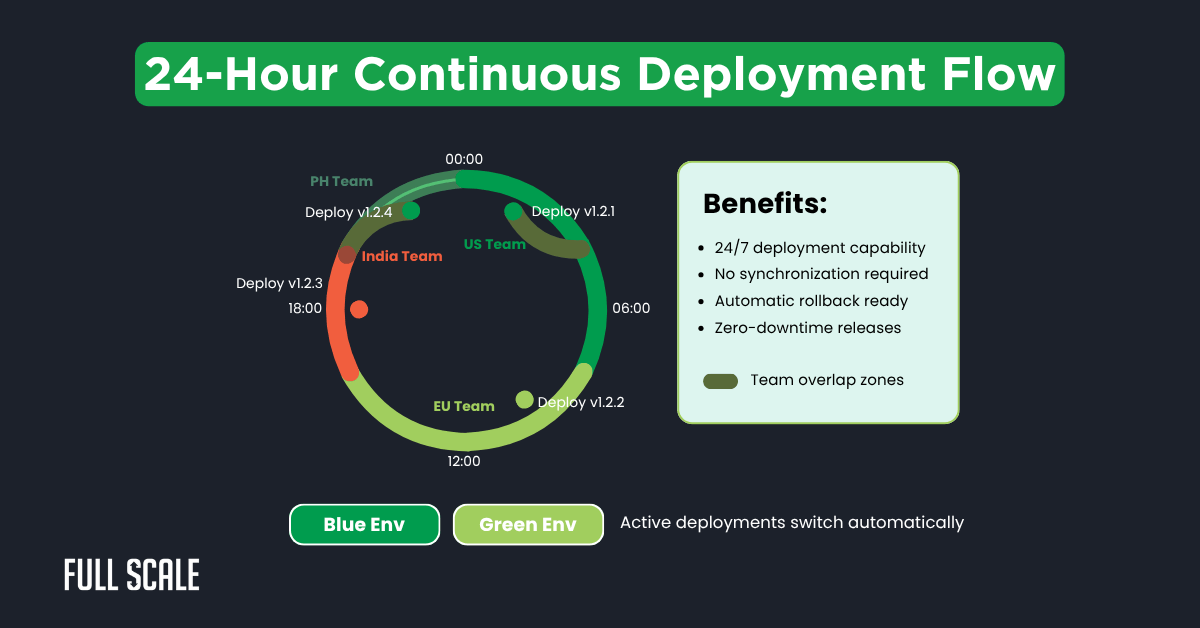
This continuous deployment cycle ensures system updates happen round-the-clock. Teams deploy during their optimal hours without coordination overhead. The overlap zones provide natural handoff points for complex changes.
Key advantages of this approach:
- 24/7 deployment capability without synchronization
- Automatic rollback mechanisms for each region
- Zero-downtime releases through gradual rollouts
- Independent team operations with full autonomy
Distributed team software architecture enables continuous delivery without synchronization requirements. Each region maintains deployment autonomy while preserving offshore development reliability. Our client’s Philippines team often deploys critical updates while other regions sleep.
Feature Flags for Progressive Rollouts
Feature flags enable remote engineering team scalability through controlled releases. Teams gradually enable features based on timezone and user segments. This approach prevents widespread failures while gathering real-world performance data.
# Feature flag configuration for distributed teams
feature_flags:
new_payment_system:
rollout_stages:
- stage: "canary"
percentage: 5
regions: ["philippines"]
start_hour: 9
end_hour: 17
- stage: "early_adopter"
percentage: 25
regions: ["philippines", "india"]
start_hour: 6
end_hour: 18
- stage: "general_availability"
percentage: 100
regions: ["all"]
monitoring:
error_threshold: 0.1
latency_p99: 500
auto_rollback: true
This configuration demonstrates distributed team software architecture best practices. Feature flags provide distributed team technical debt management through controlled rollouts. Teams validate changes incrementally without risking system-wide failures.
Monitoring and Observability for Distributed Team DevOps Practices
Effective monitoring across timezones requires intelligent alert routing and ownership clarity. Teams need visibility into system health without information overload. Smart dashboards and automated escalation ensure the right team responds to issues.
Distributed Monitoring Stack Architecture
According to the 2024 State of DevOps Report, teams using distributed monitoring see 73% faster incident resolution. Our client implemented Prometheus with team-specific Grafana dashboards for this reason. Each dashboard shows only relevant metrics for that timezone’s services.
The following table shows optimal monitoring configurations by team size:
Monitoring Configuration Table| Team Distribution | Alert Threshold | Escalation Time | Dashboard Refresh | Retention Policy | Recommended Tools |
|---|---|---|---|---|---|
| 2-3 Teams Limited timezone coverage |
Critical: 1 min Warning: 5 min |
15 minutes | 30 seconds | 7 days | Prometheus Grafana PagerDuty |
| 4-5 Teams Good timezone coverage |
Critical: 3 min Warning: 10 min |
30 minutes | 60 seconds | 14 days | Prometheus Grafana VictoriaMetrics Opsgenie |
| 6+ Teams Full timezone coverage |
Critical: 5 min Warning: 15 min |
45 minutes | 120 seconds | 30 days | Thanos Grafana Cortex PagerDuty Datadog |
- Teams with limited coverage need aggressive alerting to catch issues quickly
- Full coverage teams can use relaxed thresholds to reduce alert fatigue
- Retention policies should match your compliance requirements
- Dashboard refresh rates balance real-time visibility with system load
This configuration matrix helps teams balance alerting sensitivity with alert fatigue. Teams with better timezone coverage can afford longer thresholds. Teams with gaps need aggressive monitoring to catch issues before handoffs.
Critical monitoring principles for distributed teams:
- Alert thresholds scale with team coverage
- Dashboard refresh rates balance visibility with load
- Retention policies match compliance requirements
- Tool selection depends on team distribution
Distributed team software architecture monitoring requires a careful balance between visibility and noise. Effective distributed team monitoring prevents alert fatigue while ensuring critical issues surface immediately. Our offshore team’s code quality metrics integrate directly into these dashboards.
Incident Response Automation
Automated incident response reduces mean time to recovery (MTTR) for distributed team CI/CD pipelines. Our client automated 80% of common incidents using runbooks and self-healing systems. This automation freed developers to focus on complex problems requiring human insight.
class IncidentResponseAutomation:
def __init__(self, pagerduty_client, slack_client):
self.pd = pagerduty_client
self.slack = slack_client
self.runbooks = self.load_runbooks()
def handle_incident(self, alert):
# Determine incident severity and type
severity = self.classify_severity(alert)
incident_type = self.identify_type(alert)
# Get active team based on timezone
active_team = self.get_active_team()
# Attempt automated resolution
if incident_type in self.runbooks:
success = self.execute_runbook(incident_type, alert)
if success:
self.log_auto_resolution(alert, active_team)
return
# Escalate to human if automation fails
self.escalate_to_team(alert, active_team, severity)
def get_active_team(self):
current_utc = datetime.utcnow().hour
# Team coverage windows (UTC)
team_schedule = {
'us-team': (21, 5), # 9pm - 5am UTC
'eu-team': (5, 13), # 5am - 1pm UTC
'india-team': (9, 17), # 9am - 5pm UTC
'ph-team': (13, 21) # 1pm - 9pm UTC
}
for team, (start, end) in team_schedule.items():
if start <= current_utc < end:
return team
return 'us-team' # Default fallback
Remote team system reliability depends on intelligent automation. This approach ensures that the distributed team’s software architecture maintains stability across all time zones. Incidents resolve automatically 80% of the time without human intervention.
Communication Patterns for Offshore Development Reliability
Asynchronous communication patterns prevent bottlenecks in distributed system design patterns. Teams document decisions in code and architecture decision records (ADRs). This approach ensures knowledge transfers seamlessly across time zones without synchronous meetings.
Documentation as Code
Documentation lives alongside code in our distributed team technical debt management system. Every significant change includes an ADR explaining the decision context. Teams review these documents asynchronously during their working hours.
# ADR-042: Implement Circuit Breaker Pattern for Payment Service
## Status
Accepted
## Context
Payment service failures cascade to order processing.
Philippines team reports 3am failures requiring US team intervention.
Current retry logic creates thundering herd problem.
## Decision
Implement circuit breaker with timezone-aware fallbacks.
Each region maintains independent circuit state.
Fallback routes to healthy region automatically.
## Consequences
- Positive: 99.9% availability during regional failures
- Positive: No cross-timezone escalations needed
- Negative: Increased complexity in monitoring setup
- Negative: Additional latency for fallback routes (50ms)
## Team Assignments
- US Team: Core circuit breaker library
- PH Team: Payment service integration
- EU Team: Monitoring dashboard updates
- India Team: Load testing scenarios
This ADR format exemplifies distributed team software architecture documentation standards. Clear ownership assignments prevent confusion across timezones. Teams understand both technical decisions and their specific responsibilities.
Video Documentation Requirements
GitLab’s 2024 Remote Work Report shows teams using video documentation resolve issues 61% faster. Our client requires video walkthroughs for complex features. Developers record 5-minute explanations showing code structure and decision rationale.
Key benefits of video documentation:
- Preserves context across timezone handoffs
- Reduces misunderstandings in async communication
- Accelerates onboarding for new team members
- Creates a searchable knowledge repository
Distributed team software architecture benefits significantly from visual documentation. Asynchronous video enables offshore team code quality reviews without scheduling conflicts. Our Philippine developers often wake up to detailed video feedback from US colleagues.
Testing Strategies for Multi-Timezone Engineering Teams
Comprehensive testing across distributed teams requires careful coordination and automation. Contract testing ensures service compatibility without synchronous integration tests. Chaos engineering validates system resilience before issues impact production.
Chaos Engineering for Timezone Failures
Netflix pioneered chaos engineering, reducing incidents by 45% according to their 2023 engineering report. Our client adopted similar practices for distributed teams. They simulate timezone-specific failures to validate fallback mechanisms.
# Chaos engineering configuration for distributed teams
chaos_experiments = [
{
"name": "philippines-region-failure",
"description": "Simulate complete PH region outage",
"targets": [
{"service": "payment-api", "region": "asia-southeast"},
{"service": "order-processor", "region": "asia-southeast"}
],
"actions": [
{"type": "network-latency", "value": "5000ms"},
{"type": "service-down", "duration": "15m"}
],
"validation": {
"slo_target": 99.9,
"fallback_regions": ["us-east", "eu-west"],
"max_customer_impact": 0.1
}
},
{
"name": "cascade-failure-test",
"description": "Test circuit breaker under load",
"schedule": "0 2 * * 1", # Weekly Monday 2am UTC
"gradual_failure": true,
"monitoring_alerts": ["ops-team", "on-call"]
}
]
These experiments validate distributed team software architecture resilience. Regular chaos testing ensures the remote engineering team’s scalability under failure conditions. Teams gain confidence knowing their systems handle regional outages gracefully.
Results: Achieving 99.99% Uptime with Distributed Teams
Our client’s transformation from 99.2% to 99.99% uptime demonstrates distributed team software architecture effectiveness. Monthly downtime dropped from 3-4 hours to just 4 minutes. The architectural changes delivered measurable improvements across all metrics.
Before vs. After Metrics Comparison
The following metrics show the dramatic improvement after implementing these patterns:
| Metric | Before | After | Improvement |
| Uptime | 99.2% | 99.99% | 10x better |
| MTTR | 45 minutes | 4 minutes | 91% reduction |
| Deploy Frequency | Weekly | 3x daily | 21x increase |
| Failed Deploys | 15% | 0.5% | 96% reduction |
| On-call Escalations | 12/month | 1/month | 92% reduction |
Cost Impact Analysis
Financial benefits exceeded technical improvements significantly. Emergency fixes dropped 60% saving $50,000 monthly in developer overtime. Feature delivery accelerated 40% generating additional revenue through faster time-to-market.
The system now handles three times the traffic with the same team size. This scalability comes from architectural improvements rather than additional headcount. Teams report 80% less stress during deployments due to automated safeguards.
Key financial improvements:
- $50,000 monthly savings in emergency fixes
- 40% faster feature delivery
- 3x traffic capacity without team expansion
- 80% reduction in deployment stress
Distributed team software architecture proves its value through both technical and financial metrics. Companies achieve better offshore development reliability while reducing operational costs. Our Philippines teams particularly appreciate the reduced midnight emergency calls.
Your Distributed Team Architecture Implementation Checklist
Building reliable systems with distributed teams requires systematic implementation of proven patterns. Start with event-driven architecture to eliminate synchronous dependencies. Add circuit breakers and monitoring before scaling team size.
Essential Implementation Steps
- Implement event-driven architecture for asynchronous workflows
- Deploy circuit breakers with timezone-aware fallbacks
- Add distributed tracing with team ownership tags
- Configure blue-green deployments for continuous delivery
- Set up automated monitoring with intelligent routing
- Establish chaos engineering for failure simulation
- Create documentation-as-code practices
Getting Started with Full Scale
Full Scale helps companies implement distributed team software architecture with experienced developers. Our teams come trained in fault-tolerant systems and distributed workflows. We’ve refined these practices across 60+ client implementations in the US and beyond.
Why partner with Full Scale for distributed team software architecture:
- Pre-trained developers in fault-tolerant system design
- Proven architectural patterns from 60+ implementations
- 95%+ developer retention, ensuring knowledge continuity
- Direct integration with your existing teams
- Philippines-based teams providing optimal timezone coverage
- Cost-effective scaling without sacrificing quality
- Established DevOps practices for distributed development
According to Stack Overflow’s 2024 Developer Survey, 89% of companies plan to increase distributed team sizes. Proper architecture becomes critical for success. Our proven patterns help companies avoid common pitfalls while achieving exceptional reliability.
Build Your Fault-Tolerant Team Today
FAQs: Distributed Team Software Architecture
What is distributed team software architecture?
Distributed team software architecture is a system design approach enabling development teams across multiple timezones to build fault-tolerant applications through asynchronous patterns, automated deployments, and timezone-aware monitoring.
How do distributed teams achieve high availability?
Teams achieve high availability through event-driven architectures, circuit breakers with fallbacks, automated deployments, and comprehensive monitoring that operates independently across timezones.
What are the best practices for distributed team deployments?
Best practices include blue-green deployments, feature flags for progressive rollouts, automated rollback mechanisms, and clear team ownership boundaries that respect timezone differences.
How does a distributed team software architecture reduce downtime?
It reduces downtime by eliminating synchronous dependencies, implementing automatic failovers, enabling 24/7 deployment capabilities, and providing timezone-aware incident response.
What tools support distributed team software architecture?
Essential tools include Kubernetes for orchestration, Prometheus/Grafana for monitoring, OpenTelemetry for tracing, LaunchDarkly for feature flags, and PagerDuty for incident management.


