Machine Learning in Computer Vision: You Don’t Need a Research Lab to Ship It

In this article
- What machine learning in computer vision actually is
- Why this used to need a research lab, and why it doesn’t now
- Build versus buy: the decision nobody on the SERP makes for you
- Your data is the cost, not the algorithm
- Who you actually need to hire
- When not to build computer vision at all
- Frequently asked questions
- You don’t need a lab. You need the right engineer.
When a founder tells me they want to add computer vision to their product, the picture in their head is usually a research team. PhDs at a whiteboard, a pile of GPUs, and a year of work before anything ships.
That picture is about a decade out of date.
Most production computer vision in 2026 is engineering, not research. The hard math has been solved, packaged, and handed to you in pretrained models you can call with an API key or, for the easy cases, fine-tune in days. The work that’s left is the part most people underestimate. You have to know what to build, get the data right, and wire the model into a product that holds up when reality looks different from the demo.
I’ve spent more than twenty years shipping software in production and building engineering teams, and the pattern in machine learning for computer vision is the same one I keep seeing everywhere AI shows up. The model is the easy part now. It is the same point I make in why generative AI did not make traditional machine learning irrelevant. The judgment is the job. So before you go hire a research scientist you probably don’t need, here is what machine learning in computer vision actually requires to ship, and who you actually need to build it.
What machine learning in computer vision actually is
Computer vision is the field that lets software make decisions from images and video. Machine learning is how it does that. Instead of a programmer writing rules for what a defective part or a stop sign looks like, you show a model thousands of examples and it learns the patterns itself.
That’s the whole relationship in one sentence: computer vision is an application of machine learning, and modern computer vision runs almost entirely on a flavor of machine learning called deep learning. Artificial intelligence is the big umbrella, machine learning sits under it, and computer vision is the slice of machine learning aimed at visual data.
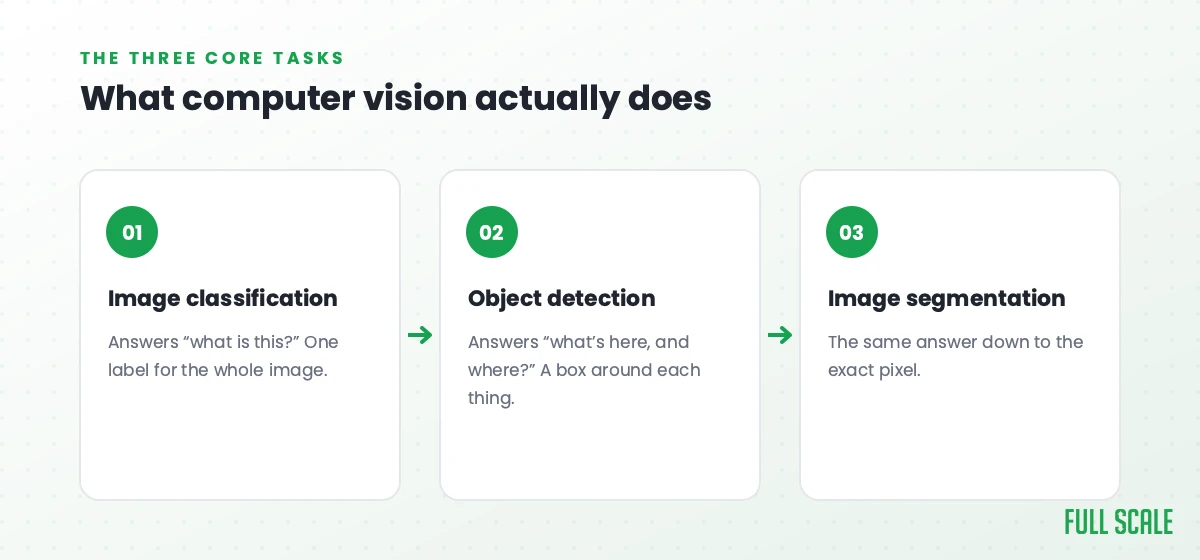
Most real projects come down to three core tasks:
- Image classification answers “what is this?” One label for the whole image. Is this X-ray normal or not, is this product photo a shoe or a sandal.
- Object detection answers “what’s here and where?” It draws boxes around each thing it finds. Counting cars in a parking lot, spotting a defect on a part, reading items on a shelf.
- Image segmentation answers the same question down to the pixel. Which exact pixels are the tumor, the road, the scratch. You reach for it when a box isn’t precise enough.
Under the hood, the workhorse for years was the convolutional neural network, or CNN, which breaks an image into pixels and learns visual patterns layer by layer. More recently, vision transformers and large foundation models have taken over the frontier. You don’t need to know the difference to make good decisions about it. It’s like running a company on a database without knowing how the engine sorts rows. What you need to know is what the models can do and what they cost you to run.
Why this used to need a research lab, and why it doesn’t now
A decade ago, building a computer vision feature meant collecting a massive labeled dataset, designing a neural network architecture, and training it from scratch on hardware you had to babysit. That genuinely was research work, and it genuinely needed researchers.
Three things changed that.
Foundation models. Big labs trained enormous vision models on internet-scale image data and released them. They have already learned what the visual world looks like, so you start from real understanding instead of from scratch.
Transfer learning and fine-tuning. You no longer train from zero. You take a model that already knows “images” and nudge it toward your specific task with a relatively small set of your own examples. Teams routinely fine-tune a useful model on a few hundred or a few thousand labeled images instead of a few million.
Vision APIs. For a long list of common problems, you don’t train anything at all. You send an image to a cloud service and get back a classification, a set of bounding boxes, or extracted text. Reading documents, moderating content, recognizing common objects, these are largely solved products you rent by the call.
The net effect: the part that used to require a research lab is now a library import or an API call. What’s left is engineering and product judgment. That’s not a knock on the field. It’s the same maturation every powerful technology goes through, and it’s good news for anyone who wants to build with it instead of publish papers about it.
Build versus buy: the decision nobody on the SERP makes for you
Search “machine learning in computer vision” and you’ll get academic reviews and vendor explainers. None of them answer the only question a CTO actually has: should I buy this off a shelf, fine-tune something, or build it myself? It’s a build-versus-buy call a lot like choosing a tech stack, and the same discipline applies.
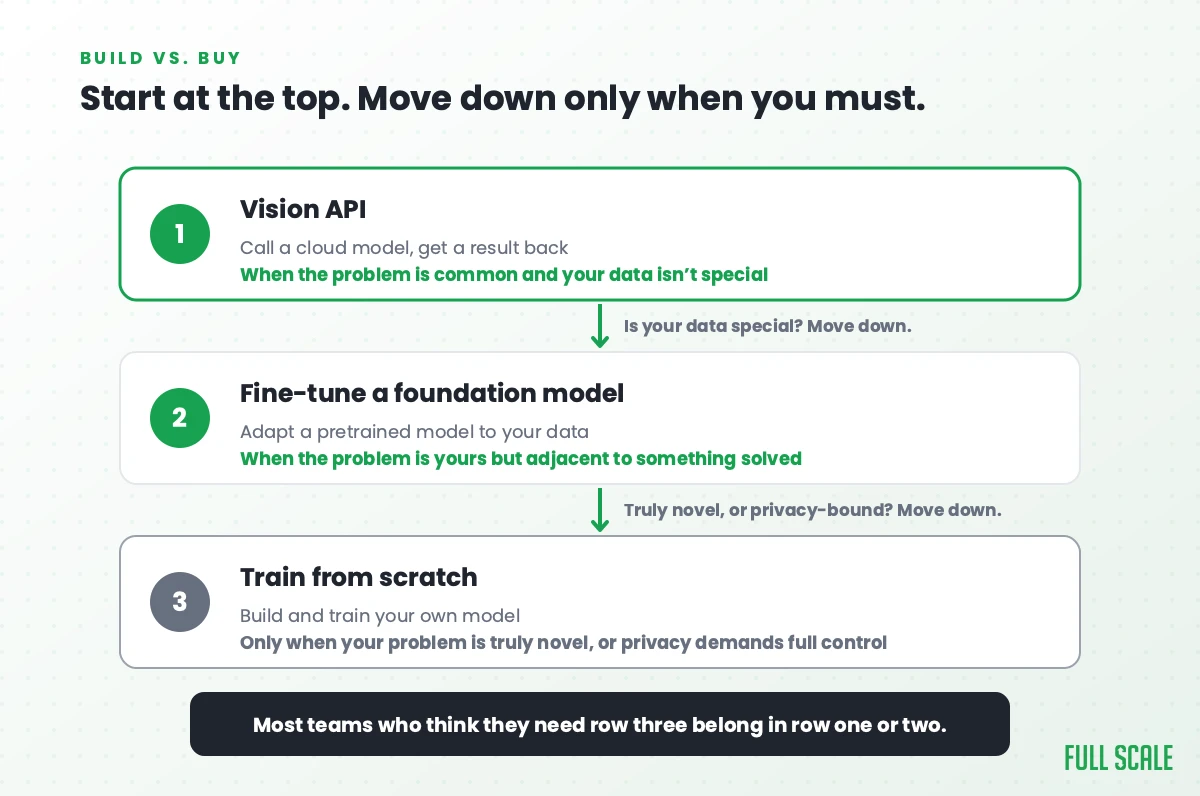
Here’s the framework I’d use. Start at the top and only move down when the row above genuinely can’t do the job.
| Approach | What it is | Best when | The cost |
|---|---|---|---|
| Vision API | Call a cloud model, get a result | The problem is common (read text, detect generic objects, moderate images) and your data isn’t special | Per-call fees, less control, your data leaves your walls |
| Fine-tuned foundation model | Adapt a pretrained model to your data | The problem is yours but adjacent to something solved (your specific defects, your documents, your products) | A labeled dataset and an engineer who knows MLOps |
| Train from scratch | Build and train your own model | Your problem is genuinely novel, or accuracy and privacy demand full control | Real time, real money, and the closest thing to actual research |
The pattern serious computer vision teams have converged on in 2026 is a hybrid: start with cloud APIs to prove the use case, fine-tune a foundation model when the generic one isn’t good enough, and only build custom when your environment is truly unique. That matches what I see with clients, and it’s the same progression that Roboflow’s roundup of computer vision companies and other build-versus-buy analyses describe. Most teams who think they need row three belong in row one or two, at least to start.
The deciding question is whether your data is special. Generic things a cloud model has already seen a billion of, like printed text, common objects, or faces, stay in row one. Visual problems specific to your world move you down: your particular defect types under your line’s lighting, your packaging, your internal documents. Privacy can force the move on its own. Medical or biometric images often can’t legally leave your walls, so for a healthcare or regulated buyer a vision API may be off the table no matter how accurate it is, which pushes you to fine-tune or run a model in your own environment.
The mistake I watch people make is starting at the bottom of that table because it feels more serious. Building from scratch when an API would do is how a three-week proof of concept becomes a nine-month research project that never ships.
Your data is the cost, not the algorithm
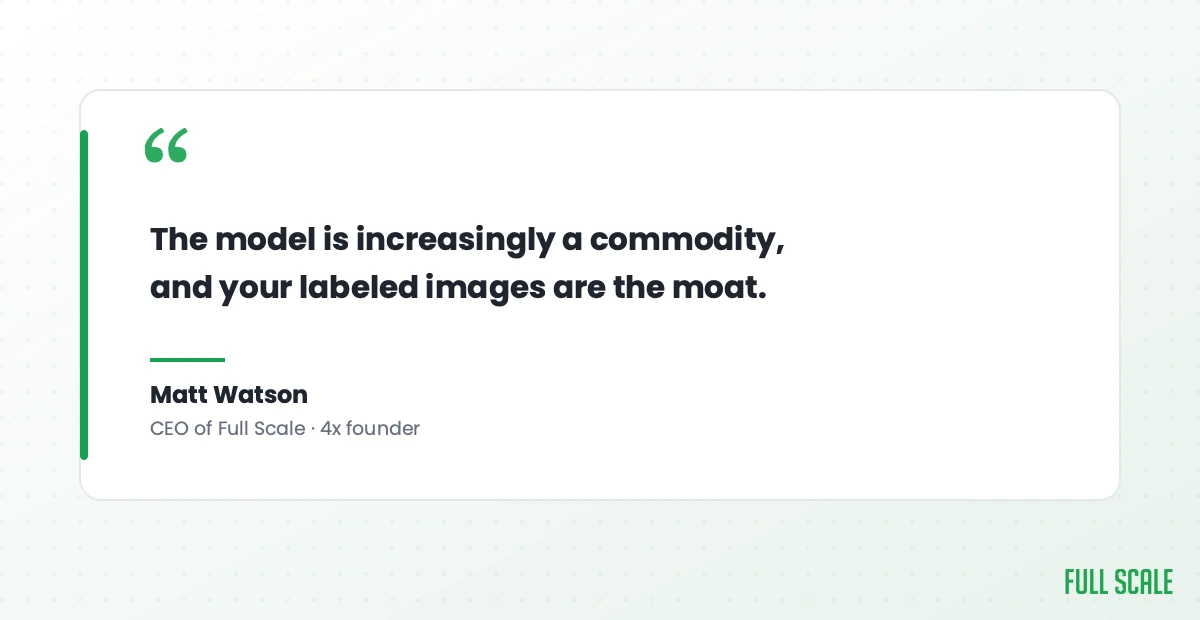
The part the textbooks bury and the vendors skip is this: in production computer vision, your data is the hard, expensive, durable part. The model is increasingly a commodity, and your labeled images are the moat.
I learned this lesson the expensive way at Stackify, the monitoring company I founded. We ingested production performance and log data at a scale no single database could hold, running roughly two thousand sharded SQL Server databases just to keep up. The algorithms that found problems in that data were never the bottleneck. Getting clean, correct, well-structured data into the system was the whole game. Computer vision is the same story with pictures instead of logs.
That means the real budget lines for a computer vision project look like this:
- Labeling. Someone has to tell the model what’s in thousands of images. This is slow, it’s tedious, and the quality of your labels caps the quality of your model. Bad labels give you bad predictions, every time.
- Edge cases. The demo works on clean images. Production sends you bad lighting, weird angles, a camera someone smeared with a thumbprint. Your data has to cover the mess, not just the happy path.
- Model decay. The world changes. New product packaging, a new camera, a new season. A model trained last year quietly gets worse, and someone has to notice and retrain it. This is MLOps, and it’s a standing cost, not a one-time build.
If you take one thing from this section, take this: when you scope a computer vision project, scope the data pipeline first. The model selection is a week of work. The data is the year.
Who you actually need to hire
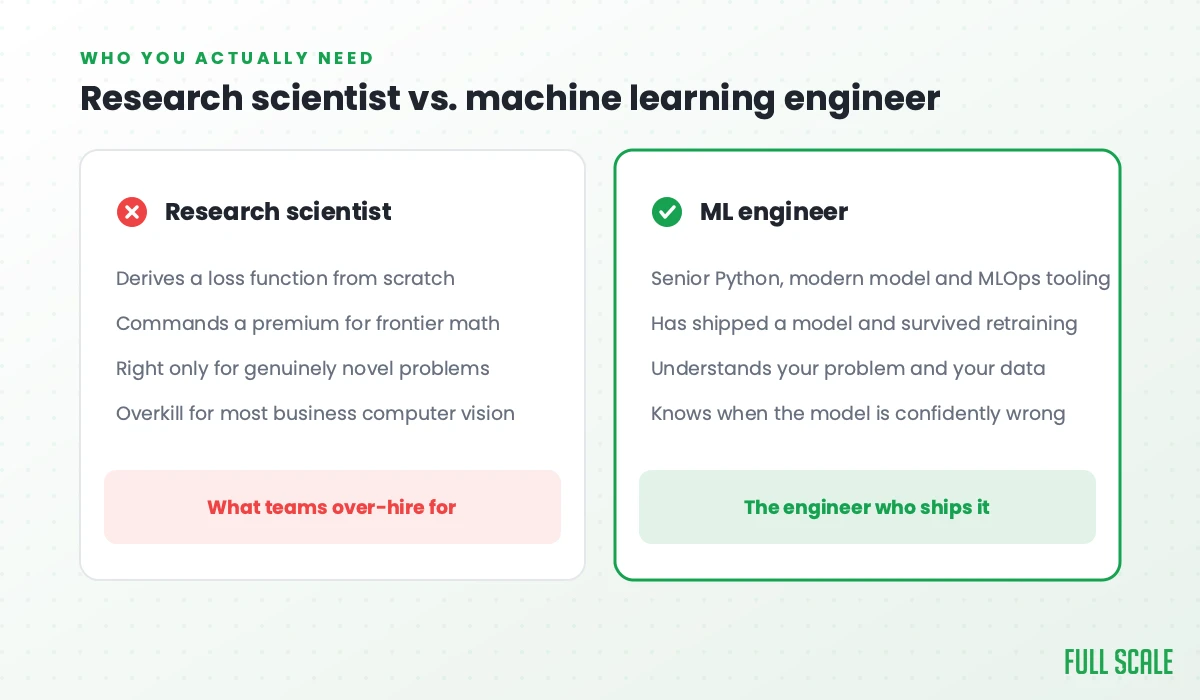
This is where the “research lab” assumption costs people real money. They go looking for a computer vision PhD, pay a premium for someone who can derive a loss function from first principles, and then hand that person a problem that needed a strong engineer who understands the business.
There are real cases where you do want research talent: a genuinely novel problem nobody has solved, frontier accuracy where one percent matters and nothing pretrained gets close, or on-device constraints that force a custom architecture. If you’re building self-driving perception or a new medical-imaging breakthrough, hire the scientists. Most business computer vision is not that.
For the overwhelming majority of production work, the computer vision developer you actually need is a machine learning engineer, not a research scientist. Someone fluent in Python, comfortable with the modern model and MLOps tooling, and above all capable of understanding your actual problem. The math is in the libraries; the judgment is in the person.
I say a version of this about every role on an engineering team now: pure coders will be replaced by AI, and problem solvers will run technology organizations. It’s even truer in machine learning. The expert in your problem beats the expert in the algorithm, because the model is downloadable and the understanding of your business isn’t. One of our engineers at SOTA Cloud used Claude to reverse engineer a proprietary dental file format that had no documentation. That’s the instinct you’re hiring for: someone who chews through your actual problem, not someone who can only recite how a CNN works.
There’s a trap waiting for teams that get this wrong. As I tell clients, AI without product thinking is just a slop machine. A computer vision model with no judgment behind it will happily return a confident, wrong answer at scale, and a confident wrong detection is worse than no detection at all. The engineer’s job is to know when the model is wrong and to build the product so a wrong prediction fails safely. That’s an engineering and product skill, not a research one, and it’s the one I screen hardest for.
Practically, the profile you want is a senior Python engineer with real machine learning experience, the kind of person who has shipped a model into production and lived through the retraining cycle. That’s exactly the bench we built at Full Scale. You can hire machine learning engineers and AI developers who work full-time inside your team, and because most computer vision work lives in Python, the same vetted bench is where you’d hire Python developers for the data pipeline and the application around the model. For a project that’s squarely an AI build from the start, our AI development services cover the whole thing. We test these engineers on real architecture and problem-solving, not on whether they can recite how a CNN works.
When not to build computer vision at all
The honest answer that the use-case listicles never give: sometimes the right call is don’t.
Skip it, or at least delay it, when the problem is rare enough that a person can just handle it, when you don’t have and can’t get the data to train on, or when a wrong answer is dangerous and you can’t yet make the model reliable enough to trust. Computer vision earns its place when the task is high-volume, visual, and repetitive enough that automating it actually moves a number you care about: defects caught, hours saved, errors avoided. If you can’t name the number, you’re not ready to build the model.
This is the same discipline I’d apply to any engineering investment. The technology being impressive is not a reason to ship it. The customer outcome is. Start from what you’re trying to change in the business, and let that decide whether computer vision is the tool, the same way it decides every other build. That’s the core argument of Product Driven, the book I wrote on building software that matters instead of software that’s merely clever.
Frequently asked questions
Is computer vision a part of machine learning or artificial intelligence?
Both. Artificial intelligence is the broad field, machine learning is a major branch of it, and computer vision is an application of machine learning focused on images and video. In practice, almost all modern computer vision runs on deep learning, which is a type of machine learning that uses neural networks.
Do I need a PhD or a research team to build computer vision into my product?
For most production work, no. Pretrained foundation models, fine-tuning, and vision APIs have turned what used to be research into engineering. What you need is a strong machine learning engineer, usually a senior Python developer with real model experience, who understands your problem and your data. Research scientists are for genuinely novel problems, which most business use cases are not.
Should I use a vision API or train my own model?
Start with an API to validate the use case, fine-tune a foundation model when the generic one isn’t accurate enough, and only train from scratch when your problem is truly unique or privacy demands full control. Most teams who assume they need a custom model can get to production faster on a fine-tuned one.
What is the most expensive part of a computer vision project?
The data, not the algorithm. Labeling images, covering real-world edge cases, and retraining the model as conditions change are the standing costs. Model selection is usually a small fraction of the work. Scope the data pipeline before you scope the model.
What are the most common business uses of machine learning in computer vision?
Defect detection in manufacturing, medical image analysis in healthcare, shelf and inventory monitoring in retail, document reading and data extraction, and quality or safety inspection in logistics. The common thread is a high-volume, repetitive visual task where automating it moves a real business metric.
You don’t need a lab. You need the right engineer.
Machine learning in computer vision stopped being a research problem and became an engineering one, and that’s the opportunity. The models are a commodity, your data is the moat, and the difference between a feature that ships and a project that stalls is the judgment of the person building it.
If you’re weighing a computer vision build and want engineers who understand the problem before they reach for the model, book a call with Full Scale. We’ll talk through what you’re trying to build and which engineers fit, with no sales pitch on the call.


