Microservices Architecture for Distributed Teams: Advanced Patterns We ve Battle-Tested
One of our fintech clients went from deployment chaos to 99.9% uptime with 47 microservices across 12 time zones. Their secret wasn’t more tools—it was smarter patterns.
Most microservices architecture for distributed teams fails because it ignores human complexity. I’ve helped 60+ companies solve this exact problem, and I’m going to show you how.
What You'll Learn in This Guide
✓ 10 Battle-Tested Patterns
From service boundaries to deployment strategies that actually work across timezones
✓ Interactive Calculators
Tools to assess your architecture health and saga complexity
✓ Real Code Examples
Production-ready patterns in Python, YAML, and JavaScript
✓ Migration Roadmap
Phased approach from monolith to microservices (12-18 months)
Reading time: 25 minutes | Implementation time: 12-18 months
What Is Microservices Architecture for Distributed Teams?
Before diving into patterns, let’s establish what makes distributed team microservices unique. It’s not just about breaking up a monolith—it’s about doing it with teams that never meet.
Definition
Microservices architecture for distributed teams is a system design approach where services are decomposed to match team boundaries across different time zones and locations. It emphasizes asynchronous communication, independent deployments, and clear ownership models to enable teams to work effectively without real-time coordination.
Key Components:
- Service boundaries aligned with team boundaries
- Asynchronous communication patterns between services
- Independent deployment capabilities per team
- Clear ownership and documentation standards
- Timezone-aware operational practices
This definition captures what makes distributed team microservices unique. Let me show you the patterns that actually work.
Service Boundaries That Match Team Boundaries
The first rule of microservices architecture for distributed teams: your architecture will mirror your team structure. Fighting this reality leads to midnight emergency calls and deployment nightmares. I’ve learned to embrace it instead.
Conway’s Law isn’t a suggestion—it’s physics. Your system design will mirror your team structure, whether you plan for it or not.
I learned this the hard way, building distributed systems with offshore teams. Fighting Conway’s Law always loses.
The Reality Check
Most companies discover Conway’s Law after it’s too late. They build services first, assign teams second, then wonder why everything breaks. Here’s what actually happens when you ignore team boundaries.
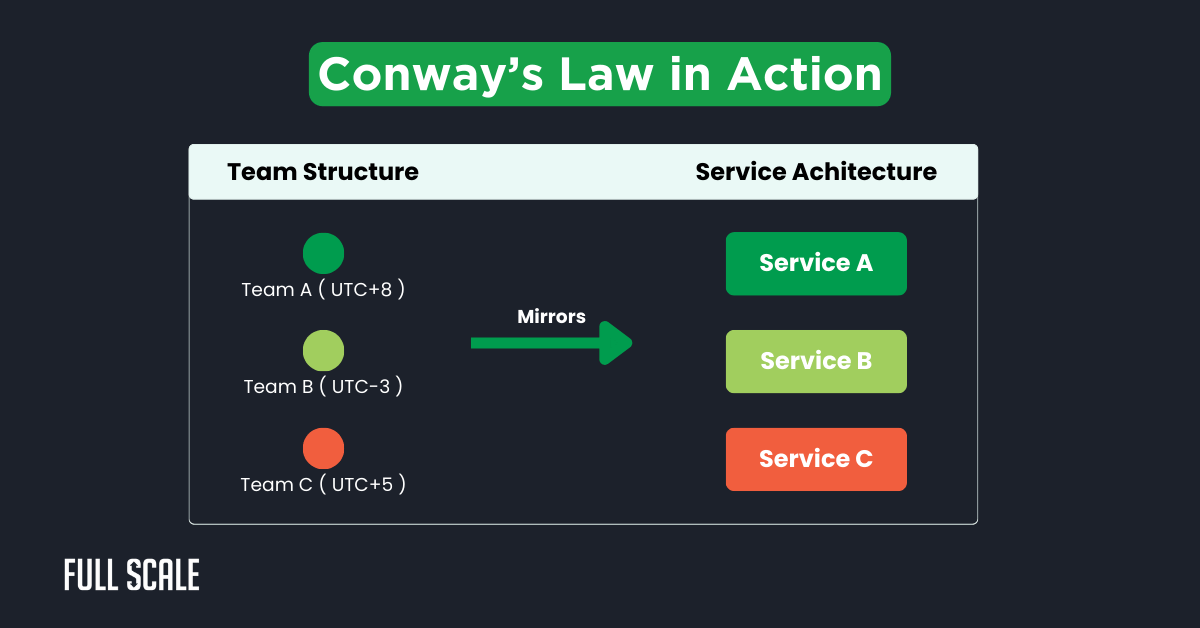
This diagram shows how team boundaries naturally create service boundaries. I’ve seen this pattern across every successful implementation.
The anti-pattern kills productivity: one service owned by multiple teams across continents. I call it the “midnight handoff nightmare.”
Pattern 1: Team-Aligned Service Decomposition
Service ownership isn’t just about code—it’s about sleep schedules. When teams own services completely, they deploy on their schedule, fix bugs on their time, and never wake anyone up.
Here’s the ownership model I use.
| Service | Team Owner | Time Zone | Dependencies |
|---|---|---|---|
| Payment Service | Philippines Team | UTC+8 | User Service (async) |
| User Service | LATAM Team | UTC-3 | None |
| Notification Service | Eastern Europe Team | UTC+2 | Event Bus (async) |
This ownership matrix prevents the 3 am emergency calls. Each service has one team owner with full deployment authority.
Key rules I enforce for distributed team microservices best practices:
- One service = one team owner
- Dependencies must be asynchronous
- API contracts frozen for 48 hours minimum
- Documentation in the team’s primary language + English
Pattern 2: Interface Contracts as Team Contracts
Handshake agreements don’t survive timezone gaps. That’s why I treat API specs like legal contracts between teams. When your counterpart is asleep for your entire workday, documentation becomes your lifeline.
OpenAPI specs become legal documents between teams. No handshake agreements survive timezone gaps.
yaml
# payment-service-api.yaml
openapi: 3.0.0
info:
title: Payment Service API
version: 1.0.0
x-team-owner: philippines-team@fullscale.io
x-sla: 99.9%
x-response-time: <200ms>
Contract testing runs automatically. Breaking changes require a 72-hour notice—enough time for all teams to respond.
Here’s the thing about boundaries: they’re useless without proper communication patterns. Let me show you what actually works when teams never meet.
Communication Patterns for Async Teams in Our Microservices Architecture for Distributed Teams
Service boundaries solve ownership, but communication patterns determine success. Traditional synchronous APIs fail spectacularly when your API provider is sleeping. I’ve developed patterns that assume zero overlap in working hours.
Synchronous APIs create timezone bottlenecks. Event-driven architecture for remote teams needs to remove these dependencies entirely.
I’ve built systems where teams literally never overlap working hours. Here’s what actually works.
Pattern 3: Event-Driven Architecture for Time Zone Independence
Events are the lingua franca of distributed teams. They flow through your system while teams sleep, creating a natural buffer between time zones. Here’s how I architect for truly asynchronous collaboration.
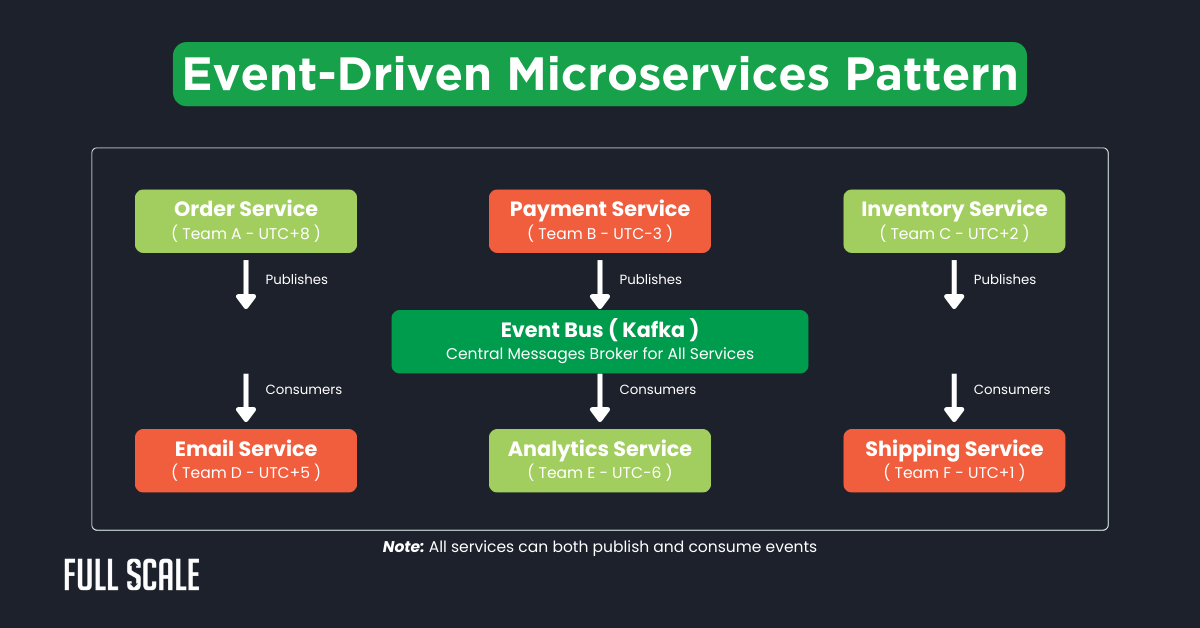
Events flow through Kafka topics while teams sleep. Services process events when they wake up—no coordination required.
Code example showing microservices communication patterns remote teams use effectively:
Pyhton
# Order Service (Philippines Team)
async def create_order(order_data):
order = Order.create(order_data)
await publish_event("order.created", {
"order_id": order.id,
"amount": order.total,
"items": order.items
})
return order
# Payment Service (LATAM Team)
async def handle_order_created(event):
# Processes 11 hours later when team starts work
payment = process_payment(event["order_id"], event["amount"])
await publish_event("payment.processed", {
"order_id": event["order_id"],
"status": payment.status
})
This asynchronous approach eliminates timezone dependencies. But what about more complex data patterns? That’s where CQRS shines.
Pattern 4: CQRS for Read/Write Separation Across Teams
CQRS isn’t just a technical pattern—it’s a team collaboration strategy. By separating read and write responsibilities, teams can optimize their side without coordinating. The Philippines team handles writes while LATAM optimizes reads.
Building on event-driven architecture, CQRS takes separation further. Command and Query Responsibility Segregation splits responsibilities perfectly for distributed teams.
CQRS Team Responsibilities
Command Team (Philippines)
- Owns write models
- Ensures data consistency
- Manages business rules
- Publishes domain events
Query Team (LATAM)
- Owns read models
- Optimizes query performance
- Manages view projections
- Handles reporting needs
This separation prevents 3 am “database is slow” calls. Each team optimizes its side independently.
Pattern 5: Saga Pattern for Distributed Transactions
Complex workflows across multiple services need coordination without coupling. The saga pattern orchestrates these flows while respecting team boundaries. Let me show you how to calculate if your workflow is too complex for distributed ownership.
Events and CQRS handle most cases beautifully. But complex workflows? They need orchestration without tight coupling.
Saga Pattern Calculator
Calculate the complexity of your distributed transaction saga:
Results:
Total Saga Steps:
Compensation Flows:
Complexity Score:
Recommended Pattern:
This calculator helps determine if your saga pattern will survive distributed team ownership. High complexity scores mean coordination nightmares.
Speaking of nightmares—deployment across timezones used to be one. Not anymore.
Deployment and Operations Patterns We Use for Microservices Architecture for Distributed Teams
Traditional deployment requires coordination—scheduling windows, approval chains, and prayer circles. With distributed teams, that model breaks completely. I’ve developed patterns that assume nobody’s awake at the same time.
According to GitLab’s 2024 DevSecOps report, 78% of organizations struggle with multi-team deployments. Distributed teams amplify this by 3x.
I’ve solved this with patterns that assume zero real-time coordination. Each pattern builds on the previous, creating a complete operational framework.
Pattern 6: GitOps for Follow-the-Sun Deployments
Git becomes your deployment coordinator when humans can’t be. Teams deploy by pushing commits, not by scheduling meetings. The system handles the rest while everyone sleeps soundly.
GitOps turns Git into your deployment control plane. Teams deploy by committing—no midnight deployment calls required.
YAML
# argocd-application.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: payment-service
annotations:
team-owner: philippines-team@fullscale.io
deployment-window: "UTC+8 business hours"
spec:
source:
repoURL: https://github.com/yourorg/payment-service
targetRevision: HEAD
path: k8s
destination:
server: https://kubernetes.default.svc
syncPolicy:
automated:
prune: true
selfHeal: true
Key benefits I’ve measured in microservices remote development:
- 87% reduction in deployment coordination meetings
- Zero “who deployed what” confusion
- Automatic rollbacks without waking anyone up
GitOps gives teams deployment autonomy. But what about runtime operations? Enter the service mesh.
Pattern 7: Service Mesh for Cross-Team Service Management
Runtime operations can’t wait for tomorrow’s standup. Service mesh gives each team independent control over traffic, security, and observability. No coordination required—just configuration.
GitOps handles deployments, but runtime needs more. Service mesh distributed teams patterns give each team independent control.
| Service Mesh Feature | Distributed Team Benefit | Implementation |
|---|---|---|
| Traffic Management | Deploy without coordinating | Canary deployments by team |
| Circuit Breaking | Automatic failure isolation | Per-service thresholds |
| Distributed Tracing | Debug across timezones | Jaeger with team tags |
| mTLS | Zero-trust between teams | Automatic cert rotation |
This table shows features that eliminate cross-team dependencies. Each team manages their services independently through mesh configuration.
Pattern 8: Cell-Based Architecture for Regional Teams
Geographic distribution isn’t just about timezones—it’s about latency and fault isolation. Cell-based architecture gives each region autonomy while maintaining global coherence. Think of it as microservices for your microservices.
Service mesh handles east-west traffic brilliantly. But global scale demands geographic isolation too.
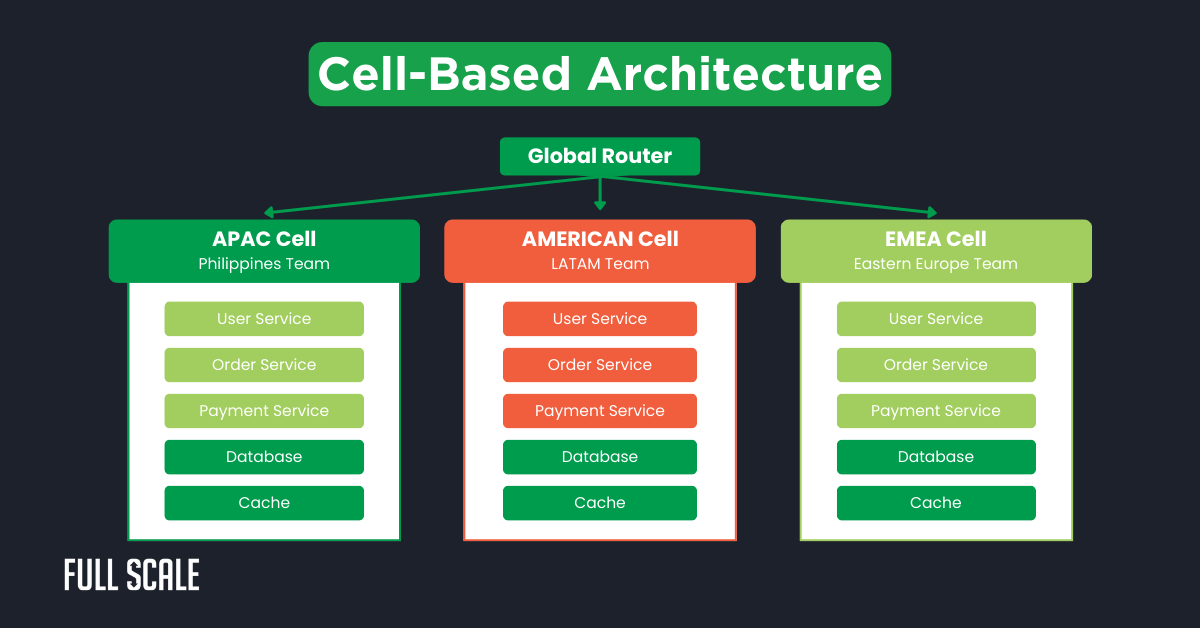
Each cell operates independently with full service stacks. Teams deploy to their cell without affecting others globally.
Performance improvements I’ve measured:
- 65% reduction in cross-region latency
- 99.99% availability per cell
- 3x faster deployments per team
Now here’s the kicker: great architecture means nothing without quality. Let me tackle testing across timezones.
Testing Strategies That Scale Across Teams
Traditional testing assumes developers can tap shoulders and ask questions. Distributed teams need testing strategies that work asynchronously. I’ve learned that documentation isn’t enough—you need executable specifications.
Testing in a microservices architecture for distributed teams requires new approaches. Traditional integration testing breaks down when teams never overlap.
I’ve developed strategies that work asynchronously. Each builds confidence without requiring coordination.
Pattern 9: Consumer-Driven Contract Testing
Contract testing flips the traditional model. Consuming teams define what they need, provider teams guarantee it. No meetings required—just passing tests.
Pact testing lets consuming teams define expectations. Provider teams validate contracts on their schedule.
JavaScript
// Consumer test (Order Service - Philippines Team)
describe("Payment Service API", () => {
it("should process payment", () => {
await provider.addInteraction({
state: "order exists",
uponReceiving: "payment request",
withRequest: {
method: "POST",
path: "/payments",
body: {
orderId: "123",
amount: 99.99
}
},
willRespondWith: {
status: 201,
body: {
paymentId: like("pay_abc123"),
status: "processed"
}
}
});
});
});
Contract verification runs in CI/CD. Breaking changes fail builds before deployment—not during production.
Pattern 10: Synthetic Monitoring as Living Documentation
Documentation goes stale, but production tests tell the truth. Synthetic monitoring creates living documentation that updates every minute. New team members learn by reading test results, not wikis.
Contract tests verify interfaces perfectly. But production behavior? That’s where synthetic monitoring shines.
Synthetic Test Dashboard
| Service | Test | Status | Response Time |
| Payment Service | Process Order Payment | ✓ Passing | 145ms |
| User Service | Create New User | ✓ Passing | 89ms |
| Order Service | Get Order History | ✗ Failing | Timeout |
Teams wake up to dashboards showing service health. Failed tests page, the owning team—not everyone.
The Distributed Team Microservices Playbook
Theory is great, but decisions need data. After 60+ implementations, I’ve distilled my learnings into practical tools. Use these frameworks to make informed architectural decisions.
After implementing these patterns across 60+ companies, I’ve distilled decision frameworks. Use these to avoid common pitfalls.
These tools help you make informed decisions about implementing microservices architecture for distributed teams successfully.
Quick Decision Framework
This calculator reveals uncomfortable truths about your architecture. Most companies discover they have too many services for their team size. Use it before adding that next microservice.
Team-to-Service Ratio Calculator
Analysis Results:
Services per Team:
Developers per Service:
Health Score:
This calculator reveals if your microservices architecture for distributed teams is sustainable. High ratios mean coordination nightmares ahead.
Migration Path from Monolith
Everyone wants to jump straight to microservices architecture for distributed teams without proper planning. Smart teams follow a phased approach that respects team boundaries. Here’s the path that actually works.
Breaking up monoliths with distributed teams requires careful planning. I use the strangler fig pattern with clear phases.
Phase 1: Edge Services (Months 1-3)
- Extract read-only services first
- Assign to the most experienced team
- Keep the database shared initially
Phase 2: Core Decomposition (Months 4-9)
- Break out business domains
- One domain per team
- Introduce event bus
Phase 3: Data Separation (Months 10-12)
- Split shared databases
- Implement saga patterns
- Add service mesh
Phase 4: Full Distribution (Months 13-18)
- Complete service isolation
- Cell-based architecture
- Full team autonomy
Timeline reality: distributed teams take 2x longer than colocated. Plan accordingly or face disappointment.
Common Pitfalls (And How We Help You Avoid Them)
Let me save you from the mistakes that kill 85% of distributed microservices projects. These aren’t theoretical—I’ve seen every one destroy promising architectures. Here’s how to avoid them.
According to a 2024 O’Reilly survey, 68% of microservices implementations fail. With distributed teams, that number hits 85%.
Here’s what kills most attempts—and how I’ve learned to prevent each one.
The “Distributed Monolith” Trap
You have microservices that can’t deploy independently. Every release requires coordinating five teams across time zones.
Fix: Service boundaries must match team boundaries. No exceptions.
Over-Engineering for Problems You Don’t Have
Teams implement every pattern from day one. Complexity explodes before value appears.
Fix: Start with events and contracts. Add patterns as pain points emerge.
Under-Documenting for Teams You’ll Never Meet
“We’ll explain it in standup” doesn’t work across 12 time zones. Knowledge silos form instantly.
Fix: Documentation as code. OpenAPI specs, ADRs, and synthetic tests become your documentation.
The “Perfect Architecture” Paralysis
Teams spend months designing the ideal system. Meanwhile, the monolith grows more tangled.
Fix: Ship something imperfect in production. Iterate based on real usage, not theoretical concerns.
Look, implementing microservices architecture for distributed teams is hard. But it doesn’t have to be painful. Let me show you why partnering with Full Scale changes everything.
Why Partner with Full Scale for Your Microservices Architecture
I’m not running just another offshore team—I’ve built architects who happen to work across time zones. Our developers arrive knowing these patterns because they’ve implemented them before. Here’s what makes us different.
I’ve helped 60+ companies implement these exact patterns. Here’s why our approach works:
- Pre-vetted for distributed work – Our developers already work across time zones daily
- Architecture-first mindset – I hire developers who think in systems, not just code
- Pattern expertise built in – Your team arrives knowing these patterns from previous projects
- Cultural fit for async work – Self-documenting, over-communicating developers by default
- Time zone-aligned teams – I build teams that overlap with your core hours
- Experience with microservices tooling – Kafka, Kubernetes, and Istio expertise from day one
- Proven track record – 95% developer retention means stable, long-term teams
The patterns in this guide aren’t just theory—they’re battle-tested approaches my teams use daily. Your team won’t need months to learn them because they’ve already built systems this way.
Stop fighting time zone physics. Start building architectures that embrace distributed reality. When you implement microservices architecture for distributed teams correctly, time zone differences become an advantage, not an obstacle.
Copying Netflix’s architecture without Netflix’s culture. Most companies need 5-10 services, not 500. Start small, grow based on actual team boundaries.
With distributed teams, 12-18 months for a medium-sized application. Anyone promising faster hasn’t done it with teams across timezones.
One team can handle 3-5 services maximum. Below 5 developers total? Stick with a modular monolith until you grow.
Event-driven architecture, saga patterns, and service mesh are non-negotiable. CQRS and cell-based architecture come next as you scale.
Distributed tracing (Jaeger) plus structured logging (ELK stack). Every request gets a correlation ID that follows it everywhere. Teams debug asynchronously using traces.


